
GPGPU : CUDA : Introduction to CUDA in a Linux Environment
As promised in an earlier article, I am continuing this series of GPGPU tutorials by jumping over to CUDA, while I wait for NVIDIA to fix the OpenCL CommandQueue concurrency issue I discovered earlier this year. NVIDIA has confirmed the bug on both GeForce and Tesla workstation drivers and a QA contact confirmed it has been handed over to their development team for work (we’ll see how long it takes before a fix is released…). Meanwhile, CUDA 7 works fine, so let’s use that. Again, the purpose of these tutorials is to provide a standalone learning tool for GPGPU programming, without relying on SDK code or IDEs. All code used in tutorials is provided free for use in my “learnCUDA” github repository.
Here are the relevant system specs of the development platform used to compile, execute and profile the software (for this article):
- Linux Mint 17.2 with XFCE4 and NVIDIA 352.30 display driver (manually installed) for Linux x64
- Intel i7-5930K
- HX426C13PB2K4/16
- 2x NVIDIA GTX 780 6GB SC
- GCC/G++ 4.8.4
- NVIDIA Cuda 7.0 SDK for Ubuntu 14.04 (manually installed from .run file from NVIDIA and not through Canonical repo).
The software is a WIP, but branches used in specific articles can be assumed to stay relatively unperturbed moving forward (I will start new branches if I want to modify something for a future article). All source code and configuration files are in the repository and easy to find, with the exception of vendor-specific definitions and libraries. The device code in this program is very simple: two buffers of floats are copied to the device(s), summed, and copied back to the host. The user can specify total buffer size, as well as the size of a single cycle of computation (the former must be an integer multiple of the latter). These tutorials aim to focus on host-side API nuances (execution queues, memory transfers, etc): more elaborate kernels can be found in the CUDA SDK.
2015-09-06 Thank you to /u/angererc on Reddit for pointing out some interesting things I should have mentioned, and for additional corrections.
1 Overview of CUDA
Beginners are encouraged to read/re-read the OpenCL/SIMD overview in my previous article. I also highly recommend reading the whitepaper for your architecture of choice (here’s Kepler).
CUDA is very similar in structure to OpenCL, but with notable differences such as a more robust compiler (nvcc) and slightly different device command queue structure (referred to as CUDA “streams”). I personally find OpenCL to be better thought out in general, but CUDA is much more pervasive and is often ahead of OpenCL in deploying interesting features. My main gripe with CUDA is the lack of event triggers for stream operations (more on that later). Without heavy user intervention, there is a lot of implicit synchronization happening, which can be annoying to deal with. Both OpenCL and CUDA revolve around some fundamental concepts:
- Device <-> Host memory operations
- Device <-> Host instruction set handling
- Synchronous/Asynchronous operations
- Profiling / Event Management
with slight differences in implementation. With respect to documentation, NVIDIA’s CUDA guides are not as succinct and, in my opinion, less intuitive to follow than Khronos group’s OpenCL standards. While going through these tutorials, I recommend having the CUDA C Programming Guide open (and bookmarked), in case further explanation is needed. If you understood the gist of OpenCL, CUDA won’t be hard to adopt. However, I will elaborate on some of the critical features.
1.1 NVCC
The Nvidia CUDA Compiler is a proprietary compiler that is packaged with the CUDA source. Unlike OpenCL, which is exclusively JIT compiled (for now, OpenCL 2.1 is introducing binary support w/ SPIR-V), CUDA code is compiled into its own binary and linked to the host executable during program compilation. When parsing a file, NVCC can separate GPU-specific code from C/C++ host code, which it passes along to gcc/g++/ICC/the-system-c-compiler-of-choice. The resultant library is contains C/C++ functions that feed the device-specific instruction set binary code to the available CUDA devices, as needed. This is one of the areas in which CUDA has been ahead of OpenCL for some time, making it easier to deploy GPU accelerated programs without having to include readily-viewable proprietary source code.
Compiling CUDA code can be done in one of two ways, depending on the needs of the programmer:
- Put all C/C++ code in a .cu file including the CUDA C kernel definition and compile all of the code into an executable with nvcc.
- Put the kernel definition and a dedicated C/C++ wrapper (just for the kernel definition) in a .cu file. Compile just the kernel definition with nvcc and the rest of the C/C++ code with gcc/g++. Then, link all of the compiled binaries (including the ones built by nvcc) with gcc/g++ into the final executable.
learnCUDA is compiled the second way, so that people can get an idea of how to write a Makefile for such a scheme.
2015-09-06 JIT compilation from source strings is now a feature: nvrtc was deployed in CUDA 7.
1.2 CUDA Streams
CUDA Streams are analogous to OpenCL CommandQueue objects. They are simply FIFO queues for executing memory and compute operations, such as cudaMemcpyAsync and enqueueing kernels. It is possible to write a program without specifying a stream. When the stream is unspecified for a particular operation, the operation is queued to the Default Stream (Stream 0). This is the case even if operations are queued for different devices and may lead to unwanted synchronization. For anything other than simple programs, it is necessary to define multiple streams. The basic stream behavior is described in the CUDA C Programming Guide:
A stream is a sequence of commands (possibly issued by different host threads) that execute in order. Different streams, on the other hand, may execute their commands out of order with respect to one another or concurrently; this behavior is not guaranteed and should therefore not be relied upon for correctness (e.g., inter-kernel communication is undefined).
This is very similar to the OpenCL command queue, but with one very important exception: out of order execution within a stream is not possible. Indeed, as stated earlier, CUDA streams are somewhat clumsier than OpenCL command queues because you are confined to FIFO operation, and can not execute operations in a complex order using event triggers, etc.
As with OpenCL command queues, concurrency between streams is possible. However, there are certain requirements that must be met:
Two commands from different streams cannot run concurrently if any one of the following operations is issued in-between them by the host thread:
* a page-locked host memory allocation,
* a device memory allocation,
* a device memory set,
* a memory copy between two addresses to the same device memory,
* any CUDA command to the NULL stream,
* a switch between the L1/shared memory configurations described in Compute Capability 2.x and Compute Capability 3.x.
If any one of these conditions is met, there will be an implicit synchronzation point that will prevent other streams from executing until the operation is complete. It will be shown in the “Default Stream, Multi Device” example of this tutorial how to initialize page-locked (pinned) memory so that devices can concurrently read/write from/to host containers.
1.3 Kernel Execution
Device instruction sets in CUDA are executed by specifing two parameters:
- Grid size : 1-3 dimensions. This is set of identifiers for work groups called “blocks”. The volume of the grid is the total number of work groups.
- Block size : 1-3 dimensions. This is the set of identifiers for threads in a work group. The block volume is the total number of threads in a block.
As with OpenCL global/work-group sizes, these dimensions are limited by the architecture, as is the total volume of blocks (the grid size can be any volume within the max dimensions). A visualization of the execution dimensions is shown in fig1. For my GK110 units:
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)

Additionally, there is a concept of “warps”: the grouping of threads that are launched at once on a Streaming Multi-Processor (SMP), aka “Compute Unit” (of which there are 12 on my die). This concept is also present in OpenCL (and it has the same name), but I ignored it earlier because I forced the runtime to do automatic optimization of work group sizes, a functionality not present in CUDA (you have to do it manually). Understanding utilization of a GPU device is somewhat complex: the GPU can be “saturated” in multiple ways, depending on what bottlenecks are met first. Kepler, for example, has the following limitations:
- Total registers per SMP: 64k (64k 32-bit registers). This is defined by declarations for device variables/containers in the CUDA C code (i.e., if each kernel requires 255 32-bit registers, you can only execute 250 threads at once per SMP (approximately, it would probably be limited to 7 warps, or 224 threads).
- Shared memory per Block: 16/32/64 kB (user-configurable on launch).
- Number of active warps per SMP: 64
- Number of active blocks per SMP: 16 (more on this later)
- Max threads per block: 1024 (as shown above)
- Max registers per thread: 255. This is the maximum declared registers per kernel.
To ensure that device throughput is saturated, all of these bottlenecks must be considered when specifying grid/block dims on kernel launches, and when writing kernel code (more on that in later sections). There is a handy CUDA occupancy calculator available online.
Note: If manually specifying work-group size in OpenCL, the hardware warp size should drive the work-group dimensions.
2 Installation
I’ve shown in a prior tutorial how to install the NVIDIA drivers and CUDA SDK on an debian based distribution. Unlike OpenCL, everything needed to develop C++/CUDA applications is already available (assuming your distribution ships with the entire GNU toolchain, etc). To clone my repository, and compile the program simply do
git clone https://github.com/stevenovakov/learnOpenCL
git checkout ss_sd
make clean program
The NVIDIA CUDA SDK has a useful hardware spec query called deviceQuery*. Compile it and run it to become acquainted with your platform’s capabilities. Here is the output for mine:
<path-to-nvidia-SDK>/1_Utilities/deviceQuery$ make
...
<path-to-nvidia-SDK>/1_Utilities/deviceQuery$ ./deviceQuery
Device 0: "GeForce GTX 780"
CUDA Driver Version / Runtime Version 7.5 / 7.0
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 6141 MBytes (6438977536 bytes)
(12) Multiprocessors, (192) CUDA Cores/MP: 2304 CUDA Cores
GPU Max Clock rate: 1020 MHz (1.02 GHz)
Memory Clock rate: 3004 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from GeForce GTX 780 (GPU0) -> GeForce GTX 780 (GPU1) : Yes
> Peer access from GeForce GTX 780 (GPU1) -> GeForce GTX 780 (GPU0) : Yes
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 7.5, CUDA Runtime Version = 7.0, NumDevs = 2, Device0 = GeForce GTX 780, Device1 = GeForce GTX 780
Result = PASS
Some of this information will influence compute capability, transfer capability (see the copy engine field), etc. Please use Google if my installation instructions are insufficient.
3 Compilation
Again, because this isn’t 1982, the host program is coded in C++. As outlined in the NVCC section, learnCUDA is compiled using g++ for all .cc files, and nvcc for all .cu files, which only contain CUDA C kernel definitions and a C++ wrapper for calling the kernel from a C++ program. As seen in “summer.cu”, the kernel is defined in CUDA C:
// summing kernel
__global__ void Summer(
float * one,
float * two,
float * out
)
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;
out[index] = one[index] + two[index];
}
and right below it is the C++ wrapper, which provides a C++-compatible function to launch the kernel:
// c++ wrapper
void runSummer(
dim3 grid,
dim3 blocks,
float * input_one_d,
float * intput_two_d,
float * output_d,
cudaStream_t * stream
)
{
Summer<<<grid, blocks, 0, *stream>>>(input_one_d, intput_two_d, output_d);
}
The <<< >>> operator is a CUDA C specific operator that launches a kernel using execution range and argument parameters. It can be abstracted as follows:
LAUNCH_KERNEL<<< dim3 GRID_DIMS, dim3 BLOCK_DIMS(, unsigned int BYTES_SHARED_MEMORY, cudaStream_t STREAM )>>> ( args... )
where the last two arguments in the <<< >>> operator, for the shared memory size and desired CUDA stream, are optional. If no stream is specified, the default stream (Stream 0) is used. Note that cuda.h must be included for any CUDA C syntax to be valid.
As with learnOpenCL, learnCUDA is compiled with a simple make clean program in shell, with an optional debug build. That should result in compiler calls that look something like this:
$ make clean program
g++ -Wall -ansi -pedantic -fPIC -std=c++11 -c main.cc -o lib/main.o -pthread -std=c++11
nvcc -arch=sm_35 -c summer.cu -o lib/summer.o
g++ -Wall -ansi -pedantic -fPIC -std=c++11 -o program lib/main.o lib/summer.o -L /usr/local/cuda/lib64 -lcudart -pthread -std=c++11
As described earlier, the C++ host code (main.cc) is compiled with g++, and the CUDA C/C++ wrapper code with nvcc. Finally, the binaries are linked together using g++.
<VERY IMPORTANT>
Note the -arch=sm_35 argument in the nvcc call. Unlike OpenCL, which JIT compiles code for itself (whatever the present runtime version already is), nvcc can compile instruction sets for newer and older architectures. It is very important that the compiler knows which architecture you are intending to run your code on. By default, nvcc will probably compile for CUDA Compute 2.X. learnCUDA will not work without modifications for architectures below 3.0. Please ensure you are using at least CUDA Compute 3.0 capable hardware if attempting to run learnCUDA as-is. I have not tested it on 5.X, but it is not using any new features so it should work (the main issue is with the maximum grid dimensions supported by 2.X, which are much smaller). For examples of compiling for different architectures, check the relevant CUDA SDK.
2015-09-06 There are some nuances here w.r.t. compiling for virtual and physical architecture, which I will not elaborate on. Passing sm_CX arguments to -arch is ok as long as no subsequent -code flag is used. See this comment.
</VERY IMPORTANT>
Though it requires more architectural knowledge than OpenCL (for simple programs), CUDA requires minimal environment setup and zero program compilation in the actual executable, which definitely reduces the volume and complexity of code, as well as setup time.
4 Execution
Unlike the intro OpenCL tutorial, which used command line profiler outputs to generate a NVIDIA Visual Profiler (nvvp) readable format, we will be executing learnCUDA code using nvvp itself! The reason for this is that NVIDIA is deprecating the command line profiler and I prefer to promote durable skill-learning. Executing the program in any of the branches tested here should yield an output like this in console:
Device Number: 0
Device name: GeForce GTX 780
Compute Capability: 3.5
asyncEngineCount: 1
Total Global Memory (kB): 6442254
Max Device Memory Pitch (kB): 2147483
Max Grid Dims (2147483647, 65535, 65535)
Max Block Dims (1024, 1024, 64)
Max Block Size: 1024
Warp Size: 32
Max Threads per SMP: 2048
Device Number: 1
Device name: GeForce GTX 780
Compute Capability: 3.5
asyncEngineCount: 1
Total Global Memory (kB): 6438977
Max Device Memory Pitch (kB): 2147483
Max Grid Dims (2147483647, 65535, 65535)
Max Block Dims (1024, 1024, 64)
Max Block Size: 1024
Warp Size: 32
Max Threads per SMP: 2048
Total Input Size: 100.000 (MB), GPU Size: 100.000 (MB), Compute Chunk: 50.000 (MB), Total Array Size: 25000000, GPU Array Size: 25000000
Generating random number sets...
Number sets complete.
N Chunks: 2, Chunk Buffer Size: 50000128 (B)
100.00% complete
Testing 20 random entries for correctness...
Entry 14674234 -> 0.6708 + 0.1199 = 0.7906 ? 0.7906
Entry 22936796 -> 0.0884 + 0.0128 = 0.1013 ? 0.1013
Entry 12799297 -> 0.2921 + 0.6547 = 0.9468 ? 0.9468
Entry 15718569 -> 0.7520 + 0.1485 = 0.9005 ? 0.9005
Entry 16246963 -> 0.7845 + 0.0469 = 0.8314 ? 0.8314
Entry 3855776 -> 0.3704 + 0.0934 = 0.4638 ? 0.4638
Entry 554074 -> 0.5694 + 0.1523 = 0.7217 ? 0.7217
Entry 14983718 -> 0.6257 + 0.2859 = 0.9116 ? 0.9116
Entry 19944209 -> 0.1956 + 0.4506 = 0.6462 ? 0.6462
Entry 18031802 -> 0.4970 + 0.6025 = 1.0994 ? 1.0994
Entry 12666540 -> 0.4740 + 0.7365 = 1.2105 ? 1.2105
Entry 7760524 -> 0.0767 + 0.3610 = 0.4376 ? 0.4376
Entry 15710979 -> 0.2664 + 0.5677 = 0.8341 ? 0.8341
Entry 15003214 -> 0.2554 + 0.3941 = 0.6495 ? 0.6495
Entry 19185088 -> 0.4102 + 0.5316 = 0.9418 ? 0.9418
Entry 18056165 -> 0.5290 + 0.5392 = 1.0682 ? 1.0682
Entry 17901486 -> 0.5920 + 0.4586 = 1.0506 ? 1.0506
Entry 20454050 -> 0.0001 + 0.1481 = 0.1482 ? 0.1482
Entry 22255658 -> 0.4926 + 0.4101 = 0.9027 ? 0.9027
Entry 9725284 -> 0.4544 + 0.3159 = 0.7703 ? 0.7703
showing the relevant device capabilities, specified buffer sizes and a sample of 20 random entries in the output buffer on completion as a visual check for correctness.
4.1 Default Stream, Single Device
If you haven’t done it already, please compile the executable in the ss_sd branch (single stream, single device), and then, load it with nvvp:
git checkout ss_sd
make clean program
nvvp program &
You should see a window as in fig2. To remove the “File does not exist” message, use “Browse…” to locate the program executable (do it anyways, or nvvp will throw out a “program not found” error). As in the OpenCL tutorial, I used a total I/O buffer size of 100 MB, and a processing chunk size (the amount processed per kernel call) of 50 MB. If you don’t care about matching my nvvp outputs, feel free to use whatever (valid) sizes you want.
<VERY IMPORTANT>
Are you experiencing errors? If you are trying to do anything too crazy (very large or very small buffers/chunk sizes, etc) you will likely experience errors. No problem, that’s what the debug build is for! Simply compile program with debug flags using make clean debug and then load it in gdb the usual way! Have fun!
</VERY IMPORTANT>
If you don’t want to tweak session profiling parameters, as seen in fig3, simply hit “finish” to watch the magic happen, otherwise, hit next and configure them (before hitting finish anyways). When execution is complete, you should see something like the output in fig4. In this case, the total session time was ~1.5 seconds. This includes (and is dominated by) initialization and allocation, as well the very small time spent doing memory transfers and compute operations at the end (shown in soccer-mom-minivan teal and vomit yellow). A zoomed in view of just CUDA stream operations is shown in fig5.
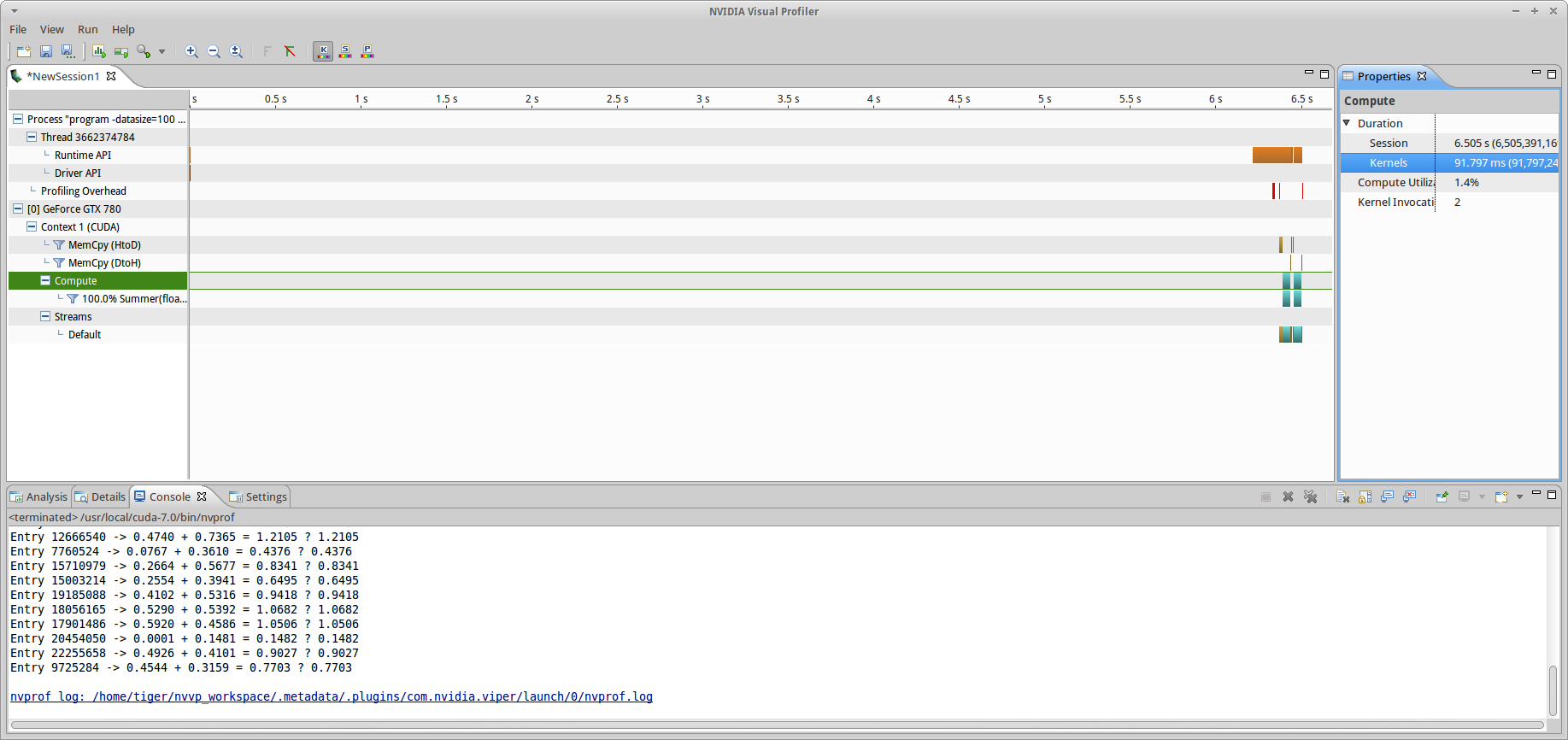
ss_sd branch with poor utilization showing complete program execution (-datasize=100, chunksize=50). The computation time is dominated by allocation of the buffers and initial data, while the actual compute time (teal + yellow) is less than 1/20 the total time.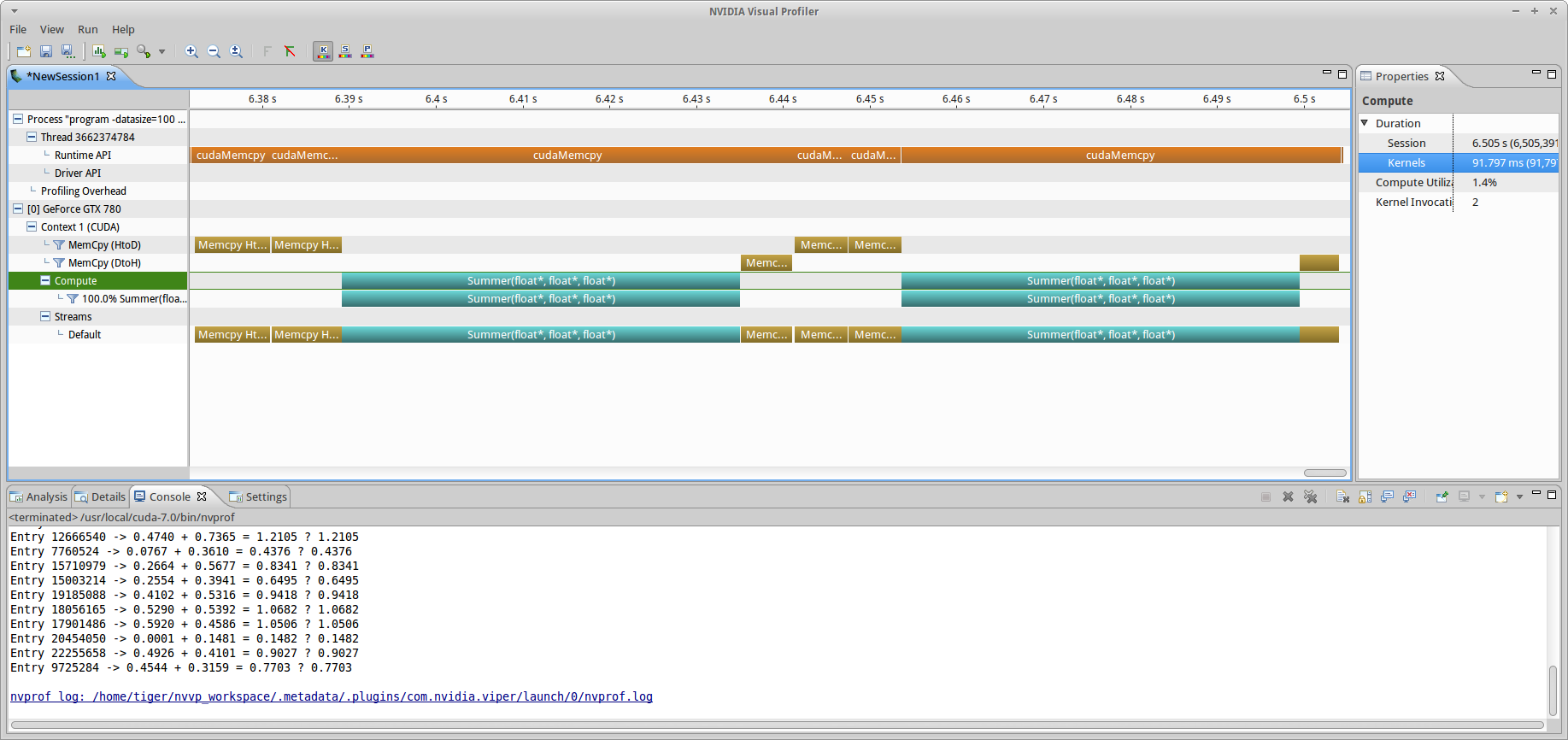
ss_sd branch (-datasize=100, chunksize=50) with poor utilization, showing just CUDA stream operations (kernel, HtoD/DtoH mem copy).This is the same sort of thing that was seen in the intro OpenCL tutorial, but astute readers will notice that the compute performance is much worse. In the OpenCL tutorial, it took ~1.4 ms of total compute time to sum 100 MB worth of floats (~14  /MB), and here it takes ~90ms, a factor of 64 higher. There is a simple explanation for this difference: in the OpenCL tutorial, I simply passed a null value to the block/work-group size parameter in the kernel enqueue, which tells the runtime to do automatic work group size optimization:
/MB), and here it takes ~90ms, a factor of 64 higher. There is a simple explanation for this difference: in the OpenCL tutorial, I simply passed a null value to the block/work-group size parameter in the kernel enqueue, which tells the runtime to do automatic work group size optimization:
err = cqs.at(d)->enqueueNDRangeKernel(
(*kerns.at(d)), // address of kernel
offset, // starting global index
compute_range, // ending global index
cl::NullRange, // work items / work group (driver optimized)
&kernel_events->at(d), // wait on these to be valid to execute
&read_events.at(d).at(0) // output event info
);
In CUDA, there is no such functionality, and, as a learning experience, I set the block dimensions to 1 (snippets from main.cc and summer.cu):
. . .
dim3 grid(n_chunk);
dim3 blocks(1);
. . .
Summer<<<grid, blocks>>>(input_one_d, intput_two_d, output_d);
Given the block dimensions (number of total threads to be queued per SMP) being just one, my utilization in this example is an incredible 1/64. This is due to two factors. First, only one thread per warp is doing useful work. The block size is (1) and threads are launched in batches of 32 (the warp size), so only one thread is writing to target memory. Second, because of the small block size (1), every single warp is from an independent block, and I am hitting the maximum blocks resident per SMP limit (16). The thread count per SMP is then 16x32 = 512, which is is half of the actual limit (1024), so 50% * 1/32 = 1/64. If this was a real job, I would already have been fired, but it’s not a job, so I casually improved upon this by filling the SMP as much as possible using the maximum block size, 1024, which should result in only 2 blocks being queued at once with full 64 wide warps (100% occupancy).
To avoid possible data corruption or overflow errors (in case my chunk size is not an integer multiple of 32), I implemented padding on the hardware buffers:
// Calculate pad for buffers so that block size can be multiple of 1024
// (which is a multiple of 32, the warp size)
std::vector<uint32_t> pads(gpus);
std::vector<uint32_t> buffer_allocate_sizes(gpus);
uint32_t buffer_io_size = n_chunk * sizeof(float);
std::vector<dim3> grids;
std::vector<dim3> blocks;
for (int d = 0; d < gpus; d++)
{
pads.at(d) = n_chunk % props.at(d).maxThreadsPerBlock;
grids.push_back
( dim3((n_chunk + pads.at(d)) / props.at(d).maxThreadsPerBlock));
blocks.push_back(dim3(props.at(d).maxThreadsPerBlock));
buffer_allocate_sizes.at(d) = (n_chunk + pads.at(d)) * sizeof(float);
printf("N Chunks: %d, Chunk Buffer Size (Device): %d (B) (%d) \n",
n_chunks, buffer_allocate_sizes.at(d), d);
}
which only introduces a minisclue performance penalty (a few extra warps on top of 1000s). Note that the memory transfers only transfer actual data: the padding is skipped and only incurs an allocation penalty.
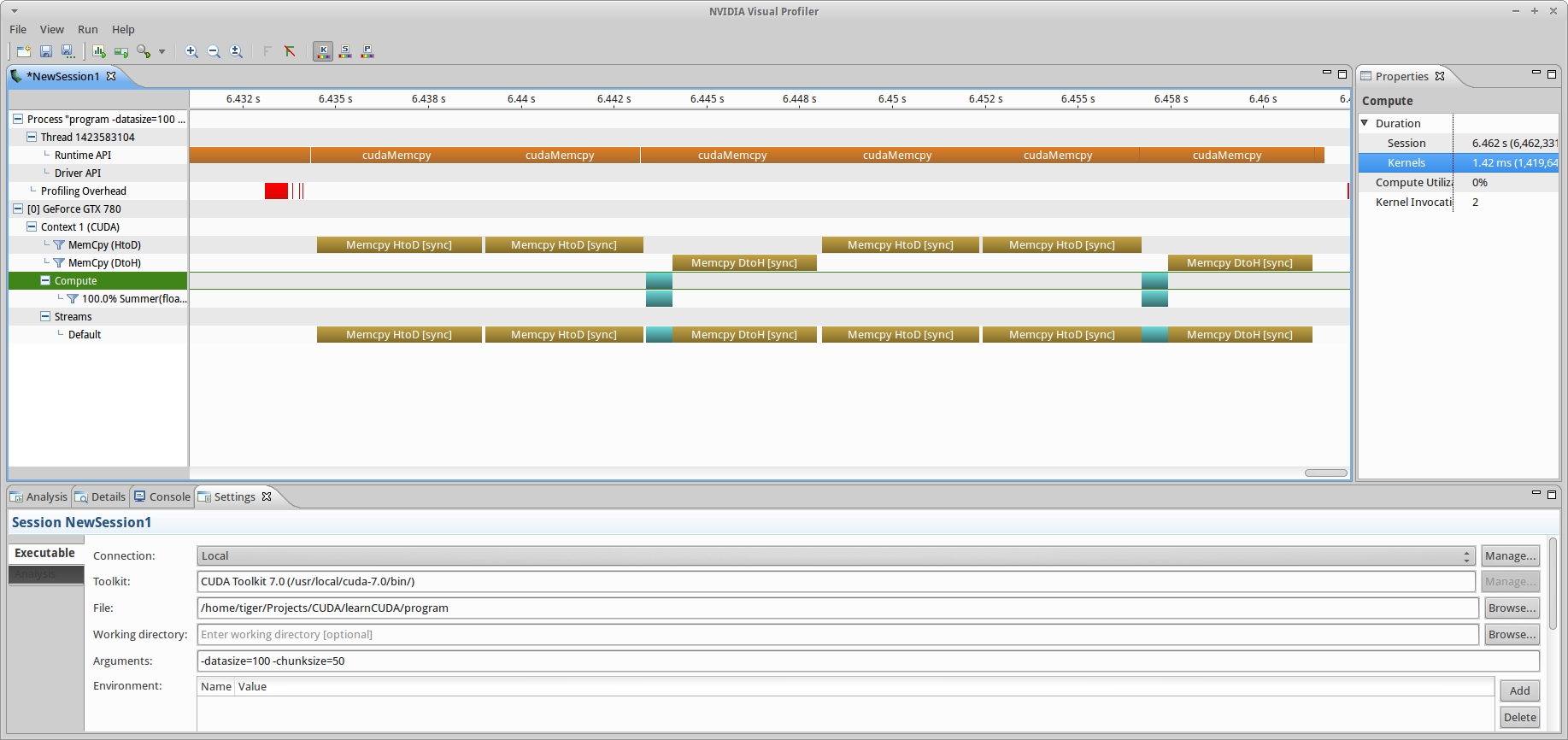
ss_sd branch (-datasize=100, chunksize=50) with full utilization. Note that the compute time (~1.4 ms) matches that of the OpenCL program in the first tutorial, when automatic optimizations were used.As shown in fig6 there is a massive improvement when we attempt to utilize as much of each SMP as possible (this is what you should see when you run this branch, the block dims of (1,1,1) was just instructional on my end). In general, a good strategy is to make the total block volume a multiple of the warp size (32). The actual multiple can be inferred from the relevant bottleneck (register count, block size, etc etc). To make your containers compatible with this size, you can implement some overflow management, such as padding, on buffers that aren’t integer multiples of 32 in size. After this fix, the total compute time is 1.426 ms, almost identical to the OpenCL time (indeed, this confirms that the OpenCL automatic optimization is working as expected!). Just to compare, via math, the performance was improved by a factor of 64.34, which confirms 100% utilization. TL;DR: under-utilization is bad, don’t do it.
4.2 Default Stream, Multi Device
If you have multiple GPUs, you can run the multi-device branches. The first branch, ss_md still only uses the default stream. Here we will see how to achieve concurrency between devices. Initializing buffers and queueing operations for both buffers on the default stream using the container structure from the ss_sd branch results in the execution shown in fig7. Note that the memory transfers are not concurrent, but that the kernel execution is. No i7 series CPU has less than 16 PCIe transceivers, so even if GPUs are operating in x8/x8 it should be possible to achieve concurrent memory transfers. The kernel execution is concurrent because the prior HtoD copies finished, and CUDA allows for up to 32 simultaneous kernel launches per device.
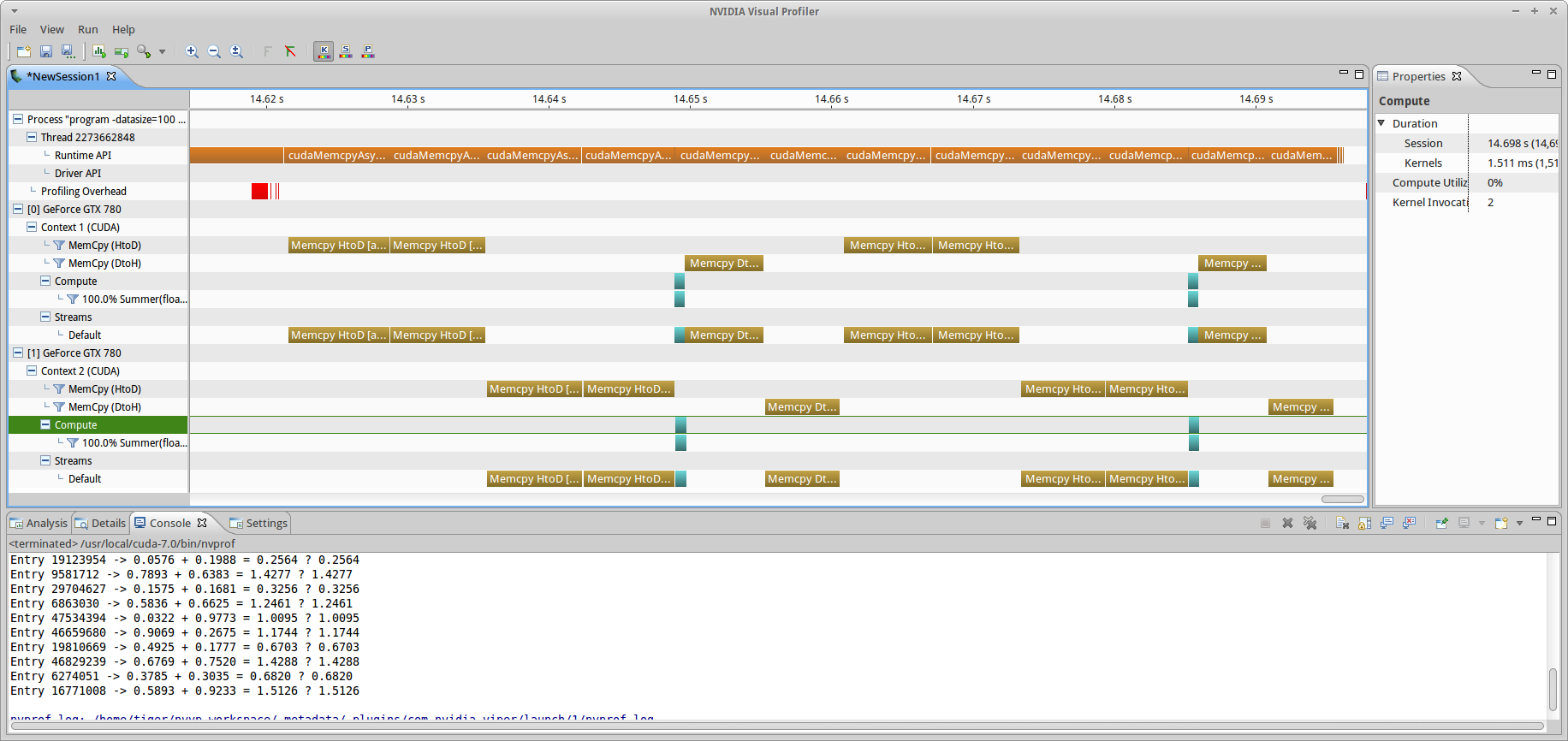
ss_md branch (-datasize=100, chunksize=50) without page-locked memory allocation host-side (for the input and output containers). Non-locked memory requires copying to a pinned buffer before it is copied to a device. This allocation and copying process creates an implicit synchronization point between stream operations that are trying to perform memory operations on non page-locked containers.So why aren’t the memory transfers concurrent? Let’s refer back to spec:
3.2.5.2. Overlap of Data Transfer and Kernel Execution
Some devices can perform copies between page-locked host memory and device memory concurrently with kernel execution. Applications may query this capability by checking the asyncEngineCount device property (see Device Enumeration), which is greater than zero for devices that support it.
The asyncEngineCount variable for my GPU is 1, so the problem is clearly that the host memory that we are copying from/to (the previously std::vector type variables input_one, input_two, and output) is not page-locked. Arrays that are allocated in C/C++ are, by default, pageable. The difference between paged and nonpaged memory pools is that paged memory can be copied to swap space and overwritten or moved to a different address block on demand, while nonpaged memory is “pinned” in place and can not be swapped, moved, or overwritten until it is explicitly de-allocated. The NVIDIA driver ensures that all buffers are physically copied from/to devices through blocks of page-locked memory. If you are calling a memory copy operation on pageable memory, the driver will first create a page-locked buffer host side and copy the data into it so that device memory transfers are uninterrupted by the OS. This creates an implicit synchronization point between all operations using a container in pageable memory. Please read this article for further explanation.
Rather than use C++ vectors, we will instead allocate the host containers using cudaMallocHost, which designates this memory as page-locked to the OS kernel. All containers allocated this way must be de-allocated at program finish using cudaFreeHost, to avoid memory leaks. The results of this change are shown in fig8.
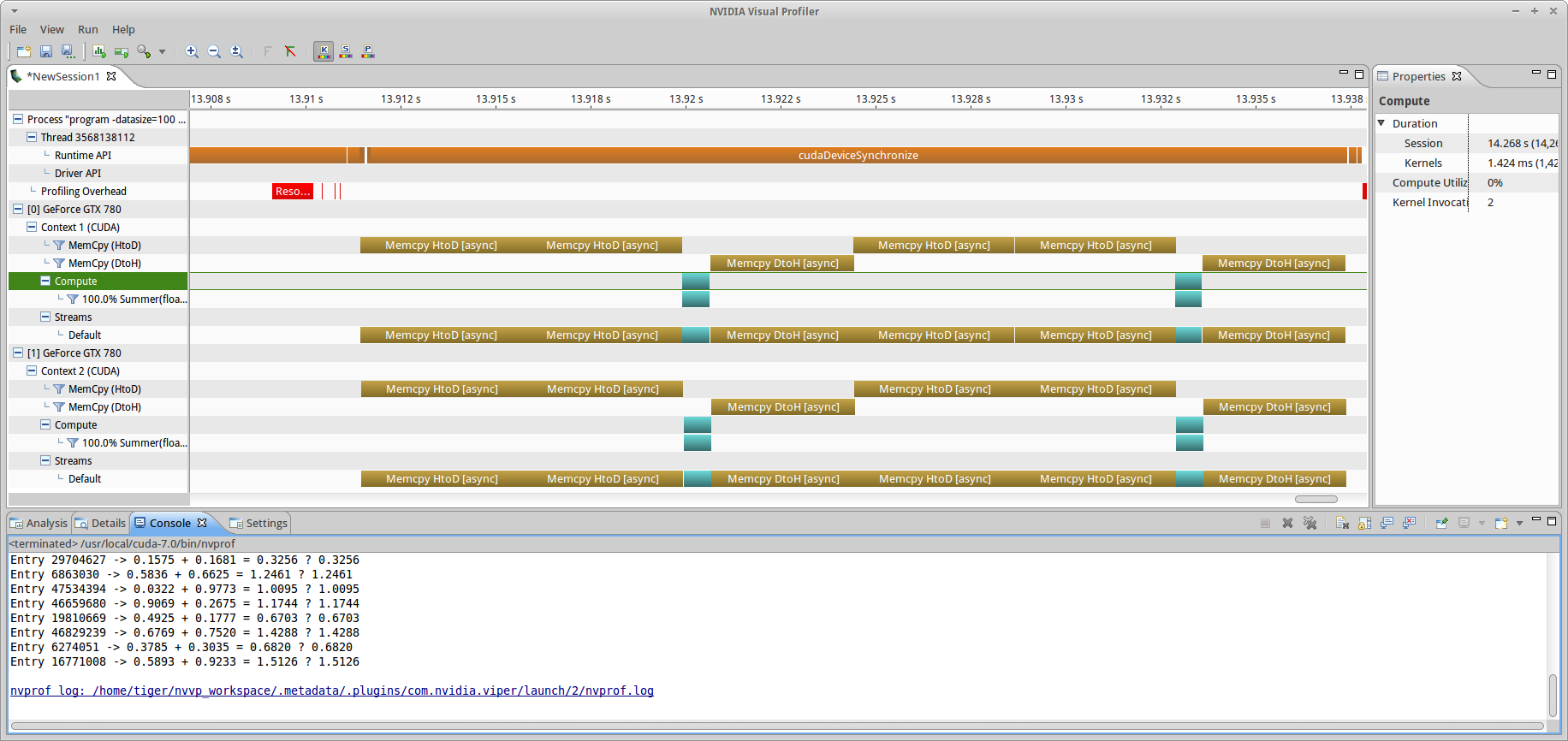
ss_md branch (-datasize=100, chunksize=50) with page-locked memory allocation host-side (for the input and output containers). Because the I/O containers are now static in RAM address space, the API allows direct copy to devices with no implicit synchronization. Concurrency between stream operations is achieved.All operations are now concurrent between GPUs. Notice that we are still only using one stream: the default. If the specification’s criteria for concurrency is met, up to 32 (at least for Kepler) operations can be queued at once. We’ll see in the last example that this is only the case for kernel launches, as memory transfers are limited by architecture.
4.3 Multi Device, Multi Stream
So far the examples have just been using the default stream, “Stream 0”. However, it is possible, in principle, to create as many streams as desired. To reiterate: streams do not operate like OpenCL CommandQueue objects. By specification, operations queued to these streams may be still be implicitly synchronized by the driver, unless conditions for concurrency are met. Also, there is an upper limit to concurrent kernel launches (32 for Kepler), so beyond a certain point, defining more streams is redundant. If only 32-way concurrency is supported, and you define 1000 streams, then the driver will serialize chunks of your 1000 streams until the hardware pipeline is saturated (32 wide kernel launches max). Also, depending on the program, using just the default stream may be sufficient, even with a fully populated motherboard (as many GPUs as physically possible). To show this, we define here one stream for each device:
for (int d = 0; d < gpus; d++)
{
cudaSetDevice(d);
cudaStreamCreate(&(streams.at(d)));
...
Any created streams must be destroyed on program completion using cudaStreamDestroy to prevent memory leaks. Stream operations must be assigned streams manually, otherwise they revert to the default. To allocate a stream for a particular device, first use cudaSetDevice. Streams created for a particular device may not operate correctly if operations are queued while another device is being used by the host thread. For correct operations, either use cudaSetDevice before switching between devices, or create multiple host threads (something I will show in a future tutorial), each dedicated to one device, and each calling cudaSetDevice upon instantiation. The kernel launches are now passed two additional parameters:
Summer<<<grid, blocks, 0, *stream>>>(input_one_d, intput_two_d, output_d);
where, as defined in the Section 3, we specify 0 bytes shared memory, and the execution stream of choice. The program execution using two streams is shown in fig9.
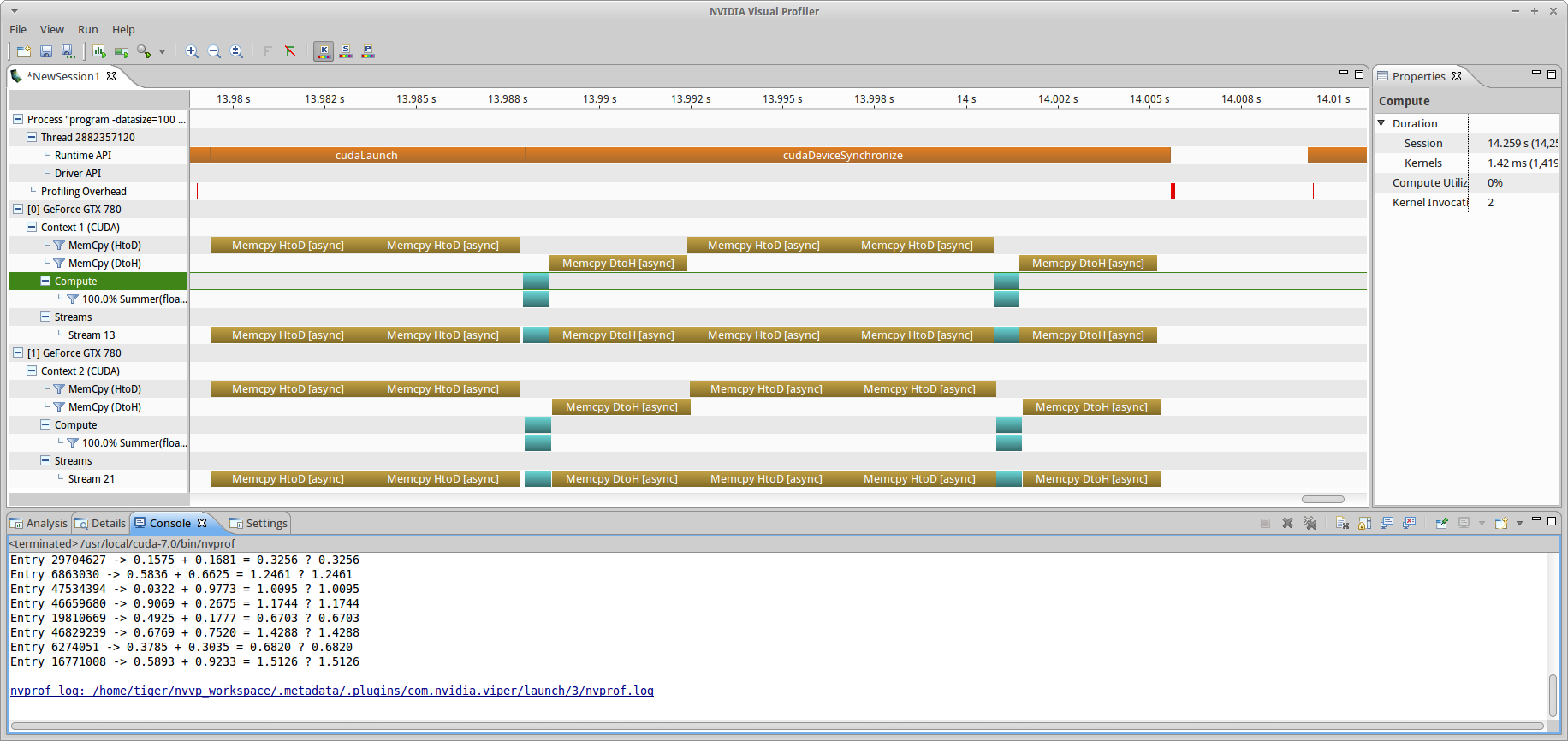
ms_md branch (-datasize=100, chunksize=50) using one stream per device. This is identical to fig8 as there is no difference between using one or two streams in this operating mode: all memory and kernel operations on separate devices meet the specification’s requirements for stream operation concurrency, so the execution is identical.This is identical to the profile obtained in fig8, where only the default stream is used. For fun, I also profiled the program when I defined two streams per device: one for HtoD memory transfers, and the other for kernel launches and DtoH memory transfers:
for (int d = 0; d < gpus; d++)
{
cudaSetDevice(d);
cudaStreamCreate(&(htod_streams.at(d)));
cudaStreamCreate(&(k_dtoh_streams.at(d)));
...
As shown in fig10, though the operations are all lauched by the streams they were assigned to. This has no effect on program execution time, and we still have not improved anything.
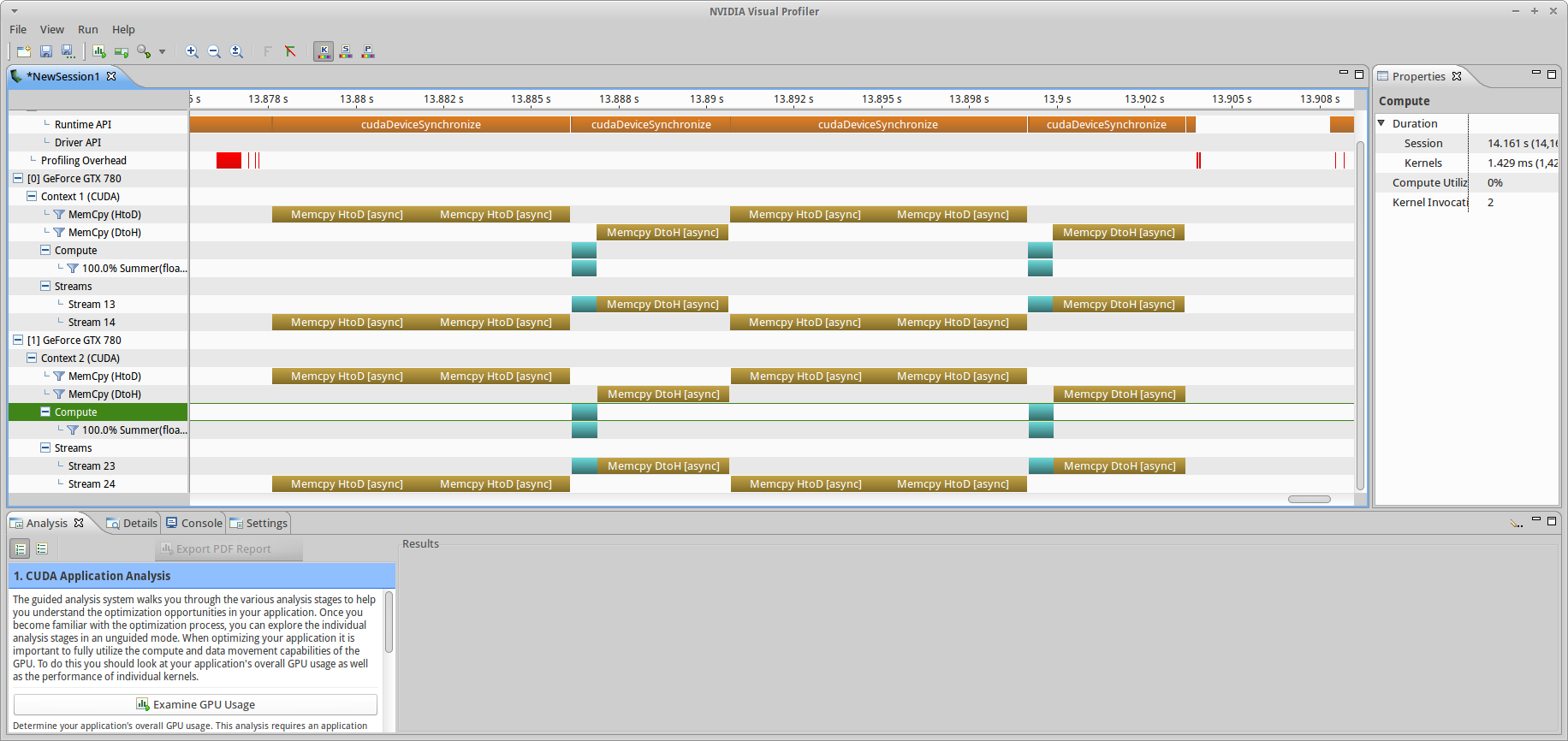
ms_md branch (-datasize=100, chunksize=50) using one stream for HtoD and another stream for kernel enqueue and DtoH. This was done to show that, because my hardware (GTX 780) only supports one copy engine, it is not possible to overlap the DtoH and subsequent HtoD operations (though it would be if a GK110 Tesla model was being used).Algorithmically, it should be possible to overlap DtoH with the next HtoD transfer and obtain correct results. However, it is not possible here because of hardware limitations. The deviceQuery output for my GPU clearly shows:
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
If this was a GK110 Tesla device, for example K10/K20, that query would look like:
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
and it would be possible to overlap memory transfers. It is not possible to achieve tight packing of operations for this program with support for only one copy engine, as all memory operations on a device are serialized, regardless of what stream they are queued on. In this example, memory operations dominate and there is minimal compute time. Future tutorials will show optimization for programs that have compute time that is similar to the memory copy time, where some interesting use of streams can lead to faster computation.
5 Conclusion
This was a simple introduction to the CUDA API. At this point, readers should have executed the first three branches of learnCUDA (ss_sd, ss_md, and ms_md) and viewed the profiling output.
Until (if) NVIDIA fixes the concurrency issue with their OpenCL environment, I will push ahead with the CUDA tutorials. The next tutorials will start to look at things like
- Further optimization/parallelization using multiple streams and multiple host threads.
- Shared Virtual Memory
- Dynamic Parallelism (launching kernels from the device)
I also plan to do a single-GPU tutorial on device fission (SMP task parallelism/MIMD) in OpenCL, which is an OpenCL 1.2 functionality that is not present in CUDA, and that has dubious proven support on NVIDIA hardware. Even though NVIDIA claim to support it, I couldn’t find any code examples of it working. Maybe this will turn into another developer zone bug report! Again, the actual kernels will try to be as simple as possible (I will try to stick with summing two buffers, unless it, for some reason, becomes awkward algorithmically), and the tutorials will continue to focus on program structure.
I’m not as experienced with CPU based OpenCL execution, and have no concrete plans for tutorials at this moment, though I may do something interesting with OpenCL and OpenMP.