
Accelerating Embrassingly Parallel Code with OpenMP and OpenACC
I recently took some time to get familiar with OpenMP and OpenACC. IÆve had ample experience with things like Jacobi/Gauss-Sidel Iteration and general PDE methods (FEM, FDTD) in numpy/MATLAB/octave. MATLAB/octave have decent single threaded performance for these types of problems, and do have some hardware acceleration capabilities. The barrier to entry for writing semi-decent MATLAB code is fairly low. However, MATLAB is limited in its scope as a general use language and I personally hate using it for anything but simple calculations (these days IÆd probably just stay with numpy/sympy/scipy, unless there was a good reason not to). Enter C++, a general purpose programming language created by Bjarne Stroustrup in 1979 at the ģ (just kidding). C++ is great, but the time investment needed to write optimized code for every architecture is, traditionally, quite large.
Enter compiler-based accelerators: One can write a lightweight single threaded algorithm, then, with literally 2-3 macros (per loop (and also careful consideration of shared thread resources (itÆs not trivial but itÆs pretty close to))), the resulting program can run on multiple CPU threads (OpenMP), or even, more recently, a GPGPU device (OpenACC), with essentially zero prior knowledge of these ISAs by the programmer.
Here are the relevant system specs of the development platform used to compile, execute and profile the software (for this article):
- Linux Mint 17.2 with XFCE4 and NVIDIA 352.30 display driver (manually installed) for Linux x64
- Intel i7-5930K
- HX426C13PB2K4/16
- 2x NVIDIA GTX 780 6GB SC
- GCC/G++ 4.8.4
- NVIDIA Cuda 7.5.17 for Ubuntu 14.04 (manually installed from .run file from NVIDIA and not through Canonical repo).
- PGC++ 15.7.0 (this is a proprietary compiler, more on that later re: installation and compilation)
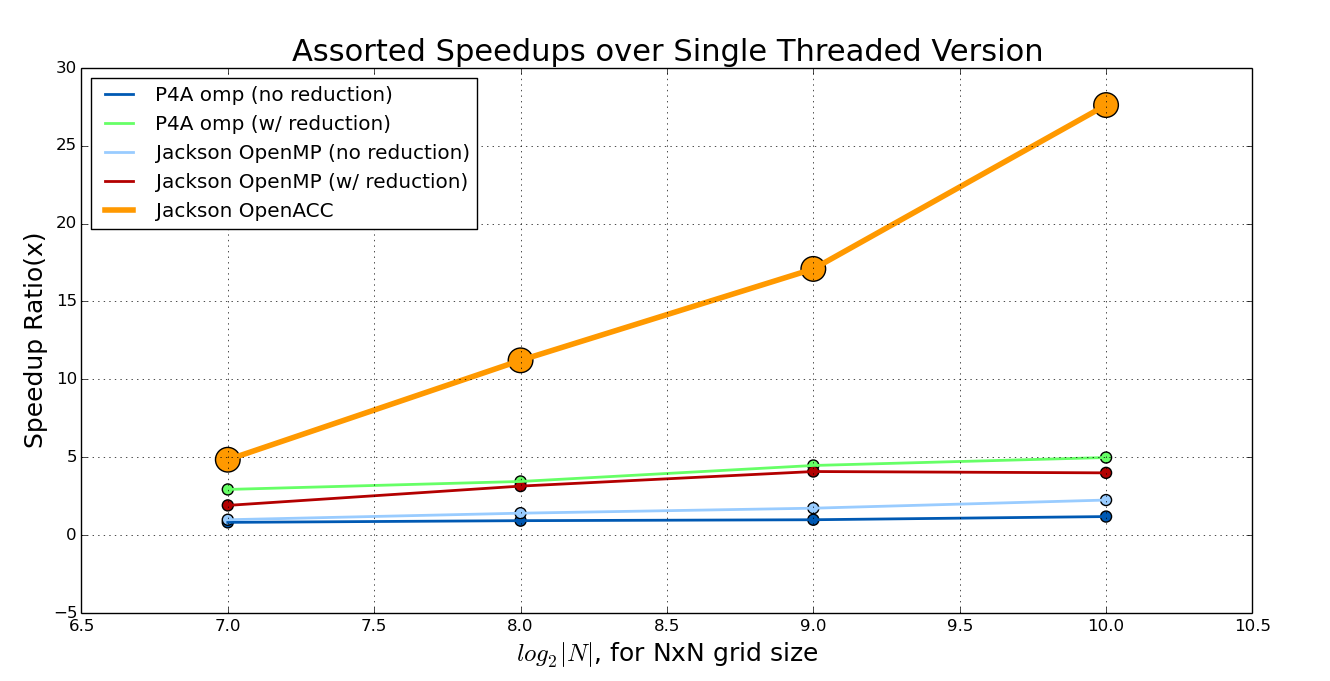
The point of this article is to showcase the OpenMP and OpenACC accelerator capabilities and provide sample code for a simple relaxation method program that solves a BVP out of the well regarded J.D. Jackson electrodynamics textbook. All of the code used in this article is available from my github repository. The main conclusions of this foray are shown in fig13 and fig14.
1 Embarassingly Parallel Algorithms
Just to give a brief overview, an embarassingly parallel algorithm is an algorithm that can be trivially broken up into parallel tasks. Most people are familar with some of these, they include:
- Matrix multiplication
- (most) Finite Difference/Element Methods
- DFT (not FFT)
For example, see Figure 9 in the CUDA Programming Guide, which shows the data I/O of a matrix multiplication algorithm. ThereÆs no inter-kernel dependency, as in the case of producer-consumer algorithms, or something more complicated that requires lots of atomic operations, etc. HereÆs pseudocode for an example program thatÆs just begging to be accelerated:
some_type global_variable;
for (uint32_t i = 0; i < l; i++)
{
for (uint32_t j = 0; j < m; j++)
{
for (uint32_t k = 0; k < n; k++)
{
data = SOURCES[i, j, k];
// ops on data
TARGET[i, j, k] = some_function(data);
}
}
}
// where SOURCES are static and independent of TARGET, for example
This is a simple nested for loop with  total size and a ōkernelö (the set of instructions that are executed for every iteration) with iteration independent (or mostly so) operations. If one were to port this to CUDA/OpenCL, they would rewrite the kernel in CUDA/OpenCL C, wrap the typical GPGPU setup/transfer/execute/cleanup code structure around it, and launch the kernel for an (l, m, n) grid size with a block size that maximizes occupancy (see my occupancy discussion in Section 4.1 of my intro CUDA tutorial). However, this requires a significant time investment, more so if the programmer has never used CUDA/OpenCL before. Fortunately, with use of various compilers and with only a few lines of code per loop structure (as you will see here, itÆs literally 1 line for OpenMP and 2-3 for OpenACC), this code can be readily compiled for parallel execution on CPU and GPGPU device. The programmer does not need to know anything about the ISA of their CPU/GPGPU: the compiler takes care of translating the C/C++ code to device-specific instruction sets and embeds their handling/execution in the pipeline of the original host code.
total size and a ōkernelö (the set of instructions that are executed for every iteration) with iteration independent (or mostly so) operations. If one were to port this to CUDA/OpenCL, they would rewrite the kernel in CUDA/OpenCL C, wrap the typical GPGPU setup/transfer/execute/cleanup code structure around it, and launch the kernel for an (l, m, n) grid size with a block size that maximizes occupancy (see my occupancy discussion in Section 4.1 of my intro CUDA tutorial). However, this requires a significant time investment, more so if the programmer has never used CUDA/OpenCL before. Fortunately, with use of various compilers and with only a few lines of code per loop structure (as you will see here, itÆs literally 1 line for OpenMP and 2-3 for OpenACC), this code can be readily compiled for parallel execution on CPU and GPGPU device. The programmer does not need to know anything about the ISA of their CPU/GPGPU: the compiler takes care of translating the C/C++ code to device-specific instruction sets and embeds their handling/execution in the pipeline of the original host code.
2 OpenMP
One option for quick acceleration of embarassingly parallel programs is OpenMP. OpenMP is a set of compiler directives that abstract the use of multithreading objects such as those in std::thread/pthread. Whenever a code region is targeted for acceleration, the programmer can simply drop in an accelerator directive, and the compiler targets that region for acceleration (it parses it and compiles binaries with multithread capabilities). In this article I use the GNU (gcc/g++) implementation of OpenMP, for all compilation and testing.
Here is how one would use OpenMP to accelerate the example nested for loop from above:
some_type global_variable;
#pragma omp parallel for shared(SOURCES, TARGET, l, m, n) reduction(fn: global_variable)
for (uint32_t i = 0; i < l; i++)
{
for (uint32_t j = 0; j < m; j++)
{
for (uint32_t k = 0; k < n; k++)
{
data = SOURCES[i, j, k];
// ops on data
TARGET[i, j, k] = some_function(data);
global_variable = some_function(something);
}
}
}
The directive above specifies that there are for loops in the proceeding region, with an iterator structure that can be parallelized. The last two directives specify the following
shared(SOURCES, TARGET, l, m, n)- The mentioned containers are shared between all threads, as opposed to thread-specific containers.reduction(fn : global_variable)- It is often the case that some status-indicative global variable is used to influence how the iteration progresses. It is optimal to specify a reduction clause so that all threads keep local copies of this global variable, update it as appropriate, and then, upon completion of all threads, the variable is resolved by whatever function (fn) is specified. Example functions include: max, sum, min (see reference card).
There are, of course, a plethora of additional directives, depending on what you want the compiler to do. For example, one can specify the maximum number of threads using the num_threads directive (here I let the compiler optimizations select the maximum thread number, which happened to be 12). OpenMP is pretty amazing on itÆs own, given that the one line turns my single threaded program into a 12 threaded program (at least on my CPU).
OpenMP, like CUDA and OpenCL, has a handy Reference Card, which is nice to look at while coding. The full OpenMP 4.0 specification is here.
3 OpenACC
Another, more recent, option for accelerating C/C++/FORTRAN code is OpenACC. This is similar in intent to OpenMP, but rather than abstracting std::thread/pthread (or whatever FORTRAN has), it abstracts Heterogeneous Computing APIs such as CUDA (NVIDIA) and OpenCL (AMD/Intel). In a nutshell, an OpenACC supporting compiler will parse the specified regions targeted for acceleration, compiling binaries with handlers and instruction sets for sending it off to the target device.
In this article I compile and benchmark code for a single GPU only (see profiling outputs below). Programming for multiple devices requires some more complication host-side (see this GPU Tech Conference Presentation for more details). I wonÆt be attempting multi GPU OpenACC software here (maybe in the future). However, I did attempt to run OpenACC accelerated code with SLI mode enabled, and was unsuccessful (see profiling outputs below).
Here is how one would use OpenACC to accelerate the example nested for loop from above:
some_type global_variable;
#pragma acc kernels
{
#pragma acc loop independent reduction(fn : global variable)
for (uint32_t i = 0; i < l; i++)
{
#pragma acc loop independent
for (uint32_t j = 0; j < m; j++)
{
#pragma acc loop independent
for (uint32_t k = 0; k < n; k++)
{
data = SOURCES[i, j, k];
// ops on data
TARGET[i, j, k] = some_function(data);
global_variable = some_function(something);
}
}
}
}
Again, this looks very similar to the OpenMP syntax, but with some important differences. Typically each nested loop structure results in one kernel being compiled. This is enforced with the kernels directive, and with wrapping the target region in {}, but that may not always be necessary (sometimes the compiler is smart). The loop independent directive is used to specify the type of parallelization desired. With the way itÆs shown above, the compiler knows to generate a work structure of kernels that are data independent (memory access is thread-exclusive), and optimally distributed on the GPU device. This is highlighted by the spec note on the loop directive:
In a parallel region, a loop directive with no gang, worker or vector clauses allows the implementation to automatecally select whether to execute the loop across gangs, workers within a gang, or whether to execute as vector operations. The implementation may also choose to use vector operations to execute any loop with no loop directive, using classical automatic vectorization.
Where ōgangsö, ōworkersö and ōvectorsö, are used to refer to the execution structure (blocks, warps, etc, see OpenACC spec). See this in-depth article by PGI for more information.
With OpenACC you have to be very careful with what functions you stick in the loop structures. User defined functions using simple operations will likely be fine. Remember that everything in the loop is compiled for the ISA of the target device. Functions with complex memory operations or regularly accessing system resources will likely result in a compiler error (see my issue with std::abs from cmath here).
OpenACC, like OpenMP, CUDA and OpenCL, has a handy Reference Card, which is nice to look at while coding. The full OpenACC 2.0 specification is here.
4 PGI Compilers
Unfortunately g++ does not have OpenACC support as of 2015-11-26 (I prefer to live in the post 1982 era, and stick to C++ whenever possible). If youÆre ok with using C (I prefer not to), gcc has had OpenACC support since ~2013-09. To be able to use OpenACC accelerator directives, you need a compiler which supports their translation (obviously). Fortunately, The Portland Group Inc. (PGI), which produces commercial HPC compilers for C, C++ and FORTRAN, does maintain a C++ compiler (pgc++) which supports OpenACC directives.
PGI compilers are proprietary. However, it is simple to get a license for a 90-day trial version from NVIDIAÆs OpenACC toolkit. If you apply for the 90 day license on NVIDIAÆs OpenACC site, PGI will send you an email with the 90 day license, as well as instructions on how to get a free yearly license if you are a student. The compilers are fairly easy to install, you just unpack the downloaded tarball and use their install script. Before you use the compilers you will have to copy and paste the license they give you into a file in the installation directory (read the installation instructions, they are included in one of the ōdocö directories of the package tarball). DonÆt forget to add the compiler binaries to your system path. For example, if you installed in /opt: export PATH=$PATH:/opt/pgi/linux86-64/15.7/bin (and add it to .bashrc or whatever the equivalent system environment startup setup file is in your distribution).
IÆm normally hesitant to endorse a proprietary solution, but I also donÆt feel like reverting back to C, so until g++ has OpenACC support, PGI it is.
5 Test Code
The test code here implements Jacobi Iteration and a similar but slightly different Relaxation Method to solve some BVP in a 2D domain. Based on some specified boundary conditions, and some arbitrary initial conditions (here the solutions are all initialized to 1.0), the relevant finite difference relation (here for the 2D laplacian) is repeatedly applied until the difference between the last iteration and the one prior is below some specified error threshold (the convergence condition).
As stated, all of the the code used in this article is available from my github repository. See the README for compilation/execution info. If youÆd like to compile and run the code (or just have something local to reference), this tutorial uses commit 7f9597f548278c8c5d5b1fefe0a22d1ebad8aac7 of the master branch. Two programs are compiled here (IÆll refer to them throughout the article as the names in parentheses):
- öJacksonö - my personal implemenation, in C++, of a solution for a BVP from the generally well regarded Jackson electrodynamics textbook.
- öp4aö - This originates from the Parallel For All blog on NVIDIAÆs developer zone. IÆve included two things here: the original (but slightly modified) C code from ōstep 3ö of the blog tutorial, as well as my own port to C++ (because 2015-1982 >> 0).
The p4a code, unfortunately, seems to only work in itÆs single threaded and OpenMP implemenations. I could not get OpenACC acceleration to function correctly for either the original source (compiled with pgcc) or my port of it (compiled with pgc++). I will discuss this in further detail below.
5.1 Jackson Problem
The Jackson problem is a simple electrostatics BVP for finding the scalar potential in the interior of a circle with radius 1, where the (constant) potential asserted on the boundary (r = 1) is:
![\displaystyle{\begin{align} V(\theta) = \left\{ \begin{array}{cr} V & \theta \in[\pi/2, -\pi/2] \\ -V & \theta \in [\pi/2, 3\pi/2] \end{array}\right.\end{align}}](https://www.stevenovakov.com/texcache/8c3e4febd86110d9c454ad387f01a8ab7ae038c7.svg)
This is solved in the region ![r = \sqrt{x^2 + y^2} \in [0, 1]](https://www.stevenovakov.com/texcache/19b1b3e2e3b7316348d497ac774470e320bae5b0i.svg) with the relaxation method outlined by Jackson (1.81), and for a source-less domain (no charge density). When you run any version of
with the relaxation method outlined by Jackson (1.81), and for a source-less domain (no charge density). When you run any version of relax (and display it using plot.py), the result should resemble the following:
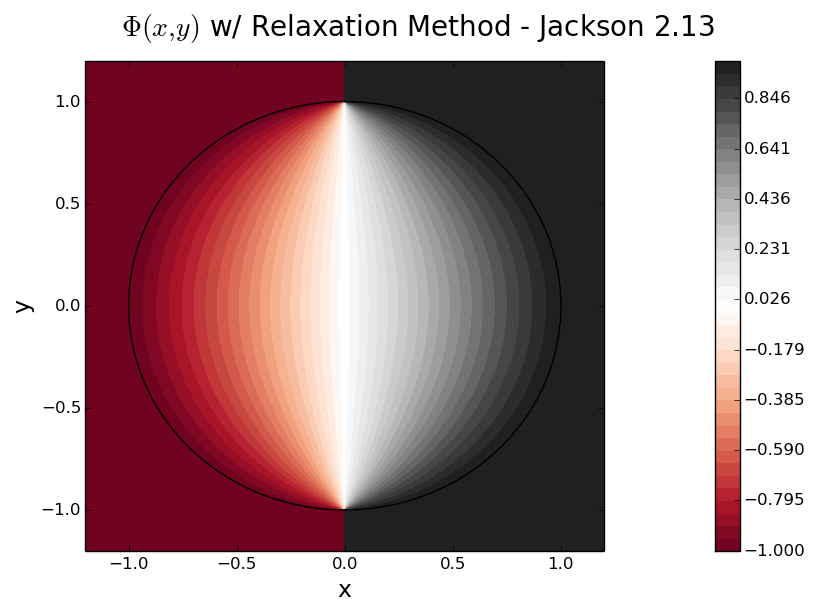
where the range is in units of V (thatÆs the RdGy colormap from matplotlib, itÆs pretty high class).
LetÆs look at the kernel for Jackson:
// for i, j \in [0, n-1]:
uint32_t ibase = i + n * j;
float x = xx[ibase];
float y = yy[ibase];
float diff;
if ( x*x + y*y > 1.0)
continue;
uint32_t iread = sel * n * n;
uint32_t iwrite = (1-sel) * n * n;
uint32_t i1 = (i+1) + n * j;
uint32_t i2 = (i-1) + n * j;
uint32_t i3 = i + n * (j+1);
uint32_t i4 = i + n * (j-1);
uint32_t i5 = (i+1) + n * (j+1);
uint32_t i6 = (i-1) + n * (j+1);
uint32_t i7 = (i+1) + n * (j-1);
uint32_t i8 = (i-1) + n * (j-1);
float pc = 0.25 * (phi[iread + i1] + phi[iread + i2] +
phi[iread + i3] + phi[iread + i4]);
float ps = 0.25 * (phi[iread + i5] + phi[iread + i6] +
phi[iread + i7] + phi[iread + i8]);
phi[iwrite + ibase] = 0.8 * pc + 0.2 * ps;
diff = std::abs(phi[iwrite + ibase] - phi[iread + ibase]);
if (error < diff)
error = diff;
Remember that this same code is executed for every pair {i,j}. This is an example of something that has relatively high compute intensity, a term used to refer to the ratio of numerical operations to memory access operations. The simple vector addition examples from my intro OpenCL and CUDA tutorials, in contrast, have very low compute intensity: two reads from memory, one addition operation, one write to memory. In general, speedup from parallelism is minimal or nonexistent for algorithms with low compute intensity. This is why I didnÆt bother benchmarking the run times of the code for those two earlier tutorials: I expect it to be about the same as single threaded CPU code.
Something that I do a little differently here, is use a single container for both the pre and post iteration solutions. Unless the iteration method is something like Gauss-Sidel/SOR, which is in-place (all operations done on one container which is itÆs own target and source), most code IÆve seen has one pre container and one post container. First the math is done on the pre containerÆs values and saved in the post container. Then, the post container is copied into the pre container, and the iteration repeats. I kind of anticipated beforehand that this method would result in multiple GPU kernels, which was confirmed when I saw the Parallel For All blog example (below). In general: a few additional FLOPS per thread are probably cheap compared to additional memory transfers, or the addition of multiple kernels (where an instruction set change is required). By using a single container, I just need to keep track of the iteration number (cheap and fast), and then use it to compute indices for successive read/writes.
5.2 Parallel For All Blog Code
While struggling to make my Jackson program accelerate correctly, I referenced this tutorial on NVIDIAÆs Dev Zone by Mark Harris. Unfortunately, this tutorial is in C and FORTRAN, though it was instructive to read. The tutorial covers a lot of concepts, however:
- ItÆs in C/FORTRAN, and not C++
- I havenÆt been able to get either the original C code or my C++ port to accelerate correctly with OpenACC.
- The benchmarking data is sparse
- The result is never shown
- The compiler discussion is sparse
That last point is fair I think, as someone trying to compile the supplied code with gcc would get pretty much zero speedup from the OpenMP version. The -fast flag equivalent for gcc/g++ is -Ofast: IÆm guessing thatÆs how the PGI compiler figures out to reduce the error variable. Without a reduction clause for the error variable, each thread is trying to update error every iteration, which stalls arithmetic (see fig12). The reduction clause in the OpenMP directive tells each thread to keep a separate, local copy of error, and then, upon completion of all threads, to reduce to some final value as per the specified function (in this case, max). Also, the fact that this code provides no way to look at the result is kind of bizzare. IÆve noticed this trend in several NVIDIA CUDA SDK code samples, such as their asynchronous vector addition, where some instructions are executed on the GPU, with no (convenient) way to check the consistency of the result. IÆm not sure how one would know whether their data was correct or just garbage (which mine ends up being when I run p4a, see below). Luckily the single threaded and OpenMP accelerated version of p4a work fine (in my C++ port, anyway). The correct result looks like this:
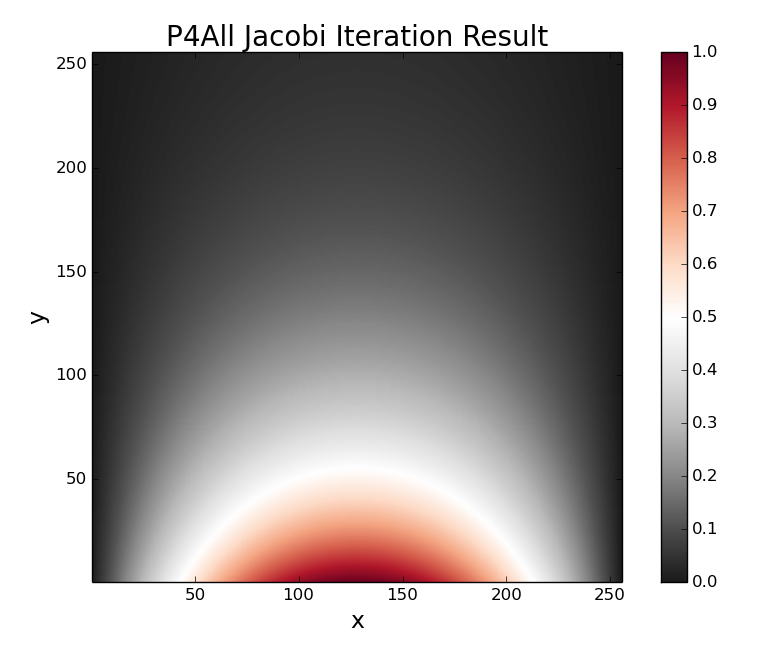
./p4a_omp -n=128 result. This is also the result for ./p4a -n=128 (the single threaded version) and is seemingly correct.which is the solution for a potential held at zero at x=0,L, y=L, and at some positive, nonzero V at y=0 inside a square box of length L. The C++ portÆs OpenACC accelerated version p4a_oacc does not compile correctly for me. The original C code does compile correctly using pgcc, however, the result is always blank:
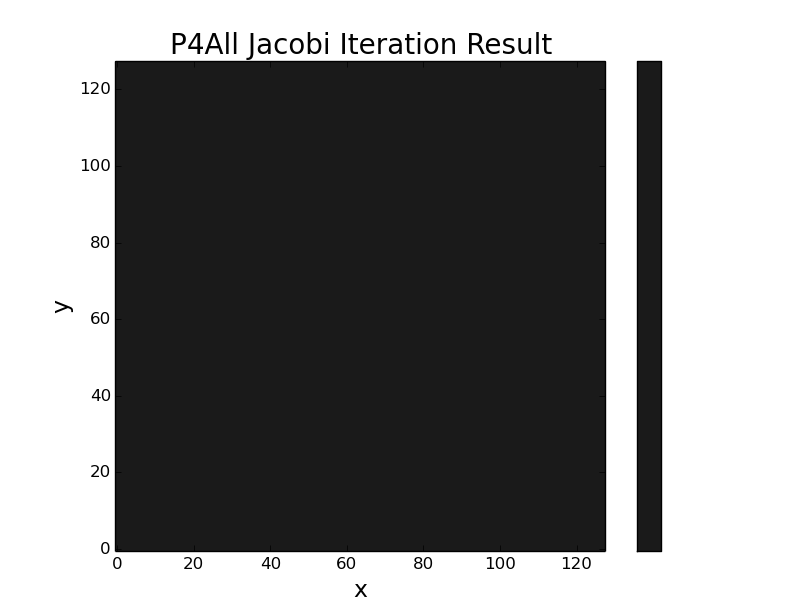
./p4ac 128 result: the OpenACC accelerated C code from the Parallel For All post. I could not get my C++ port of the p4a Jacobi Iteration code to compile correctly w/ OpenACC at all. The C code did compile and seemingly execute, but the result (shown here) is incorrect.The authorÆs final version of this code, with the final OpenACC optimizations (that I canÆt testģ), can be found here.
IÆm not interested in spending more time to get the p4a program (either p4ac or p4a_oacc) to function correctly with OpenACC, since all three versions of my Jackson code (relax, relax_omp, relax_oacc) work well and produce the correct result. However, if anyone spots an obvious error in either my port p4allrework.cc or the original-ish code in p4a.c, please let me know and I will correct it (and notify the original author).
5.3 Compilation
The code from my repository compiles two different programs: relax and p4a, each with a single threaded (no suffix), OpenMP (omp suffix) and OpenACC (oacc suffix) variant. I also compile the C version of p4a with pgcc, as it does compile and execute without fatal error (though it does not produce the correct result, see above). To compile all working (p4a_oacc does not compile without error, IÆve commented it out), just drop a make clean all in the root directory of my cloned repo:
$ make clean all
g++ -Wall -ansi -pedantic -fPIC -std=c++11 -o relax relax.cc
g++ -Wall -ansi -pedantic -fPIC -std=c++11 -o relax_omp relax.cc -fopenmp -lpthread -D OMP
pgc++ -acc -ta=nvidia:managed,time -Minfo=accel -fast -std=c++11 -D OACC -o relax_oacc relax.cc
main:
143, Generating copyin(yy[:],xx[:])
Generating copy(phi[:])
146, Loop is parallelizable
151, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
146, #pragma acc loop gang /* blockIdx.y */
151, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
Max reduction generated for error
std::abs(float):
29, include "cmath"
21, include "cmath"
88, Generating implicit acc routine seq
g++ -Wall -ansi -pedantic -fPIC -std=c++11 -o p4a p4allrework.cc
g++ -Wall -ansi -pedantic -fPIC -std=c++11 -o p4a_omp p4allrework.cc -fopenmp -lpthread -D OMP
pgc++ -acc -ta=nvidia:managed,time -Minfo=accel -fast -std=c++11 -D OACC -o p4a_oacc p4allrework.cc
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 174)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
PGCC-S-0053-Illegal use of void type (p4allrework.cc: 177)
main:
120, Generating copy(A[:])
Generating create(Anew[:])
131, Complex loop carried dependence of A->,Anew-> prevents parallelization
Parallelization would require privatization of array Anew[:]
Sequential loop scheduled on host
136, Complex loop carried dependence of A->,Anew-> prevents parallelization
Inner sequential loop scheduled on host
Accelerator scalar kernel generated
155, Generating copy([:])
158, Complex loop carried dependence of Anew->,A-> prevents parallelization
Parallelization would require privatization of array A[:]
Sequential loop scheduled on host
163, Complex loop carried dependence of Anew->,A-> prevents parallelization
Inner sequential loop scheduled on host
Accelerator scalar kernel generated
PGCC/x86 Linux 15.7-0: compilation completed with severe errors
make: *** [p4a_oacc] Error 2
pgcc -fPIC -acc -ta=nvidia:managed,time -Minfo=accel -fast -o p4ac p4a.c
main:
90, Generating copy(A[:][:])
Generating create(Anew[:][:])
96, Loop is parallelizable
99, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
96, #pragma acc loop gang(32), vector(16) /* blockIdx.y threadIdx.y */
99, #pragma acc loop gang(16), vector(32) /* blockIdx.x threadIdx.x */
103, Max reduction generated for error
108, Loop is parallelizable
111, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
108, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */
111, #pragma acc loop gang(16), vector(32) /* blockIdx.x threadIdx.x */
Note that, as mentioned earlier, p4a_oacc (my C++ port) does not correctly accelerate with OpenACC. I am unsure as to why this is the case, but from the log dump there it seems there is some unresolvable inter-kernel dependence on A, Anew. Again, as stated, I find this copying strategy to be suboptimal for this type of iterative method (see reasons in prior subsection). IÆm not going to take time right now to try and see what the problem is as my Jackson code works well.
6 Execution, Profiling
I wonÆt discuss the single threaded executables: theyÆre boring: they work fine. I ran all tests here with the error threshold float epsilon = 1.0e-5f;, so that I didnÆt have to sit around all day and wait for the single threaded runs to complete, so your execution time may change given a different error threshold. I did notice that this error threshold did not guarantee convergence for grid sizes of about 1024 and larger. I did get the correct solution by decreasing epsilon to 1.0e-6f. IÆll have to re-read my Numerical Methods class notes on what a rigorous convergence condition looks like, but IIRC, we used a constant, manually set threshold in that class as well. Intuitively, it does make sense to me that a larger grid size will converge slower and that a dual mesh method would converge faster than a single mesh method, but IÆm unsure as to the efficacy of the convergence condition

where  is the solution domain, i is the iteration number and
is the solution domain, i is the iteration number and  is some manually specified error. It seems to me that for finer mesh spacing this threshold may be reached sooner, before actual convergence. I may figure this out in the future and update this code/post appropriately.
is some manually specified error. It seems to me that for finer mesh spacing this threshold may be reached sooner, before actual convergence. I may figure this out in the future and update this code/post appropriately.
6.1 OpenMP Test
The OpenMP accelerated relax and p4a functioned as expected, with all 12 of my available CPU threads ramping up and doing work. However, relax became problematic for grid sizes of 1024 x 1024 and larger. IÆm not sure if this is due to some sort of caching issue, or whether thereÆs a problem with my code, but, as seen in fig5 and fig6, the threads become much less saturated at these larger grid sizes.
./p4a_omp -n=512 followed by a few seconds of ./relax_omp -n=512. Qualitatively, it seems as though both threads are consistently busy.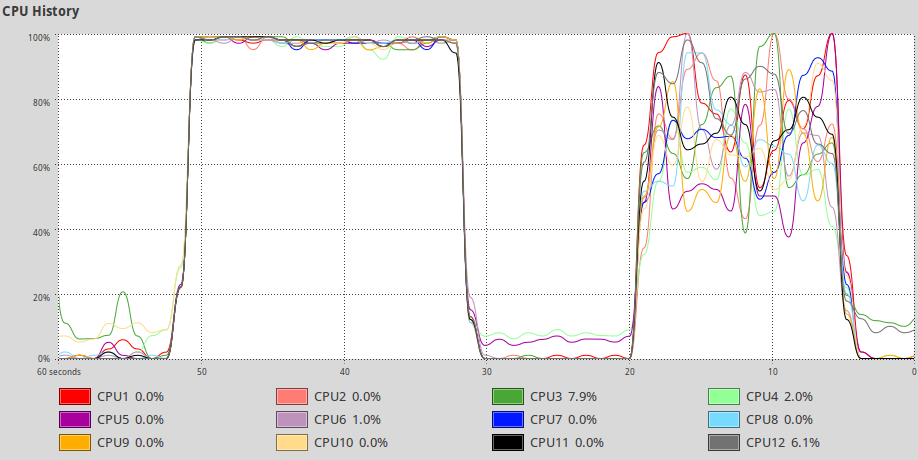
./p4a_omp -n=1024 followed by a few seconds of ./relax_omp -n=1024. It is obvious that relax_omp seems to have some issues with keeping threads busy at this larger grid size (for reasons unknown).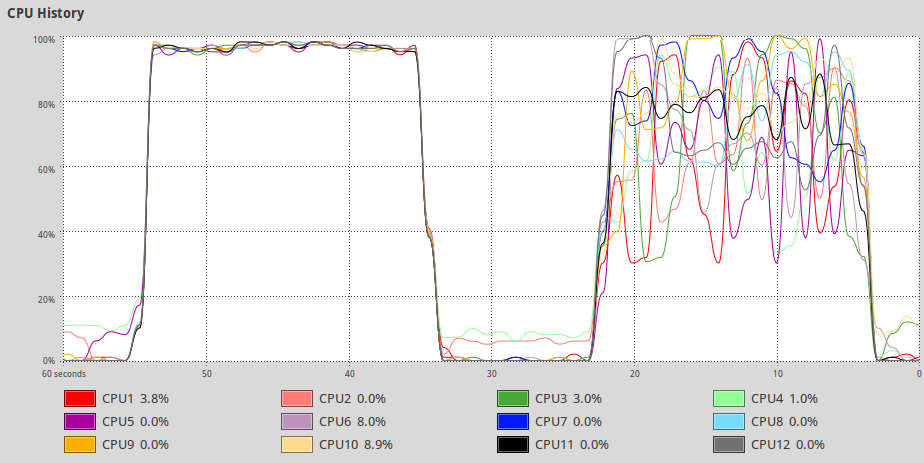
./p4a_omp -n=2048 followed by a few seconds of ./relax_omp -n=2048. With an even larger grid size, the problem is exacerbated, and relax_omp takes even longer than expected per iteration.Interestingly, p4a_omp did not have this problem, and exhibited the same behaviour (and speedup) for grid sizes up to 10,000 x 10,000 (if you want to see how that turns out, make sure you tell your grandchildren not to turn the computer off). The actual speedup for some select grid sizes is shown in fig13.
6.2 OpenACC Test
Luckily OpenACC can be visually profiled both for both NVIDIA (with nvvp) and AMD (with CodeXL) systems. Using the visual profiler, it was neat to see the exact breakdown and timing of the iteration, as shown in fig8. There is this ōmystery kernelö in there (in purple). IÆm not 100% sure, but I gather thatÆs to do with the reduction method for the error variable, due to the last 3 lines of compiler output from the acceleration:
Max reduction generated for error std::abs(float):
29, include "cmath"
21, include "cmath"
88, Generating implicit acc routine seq
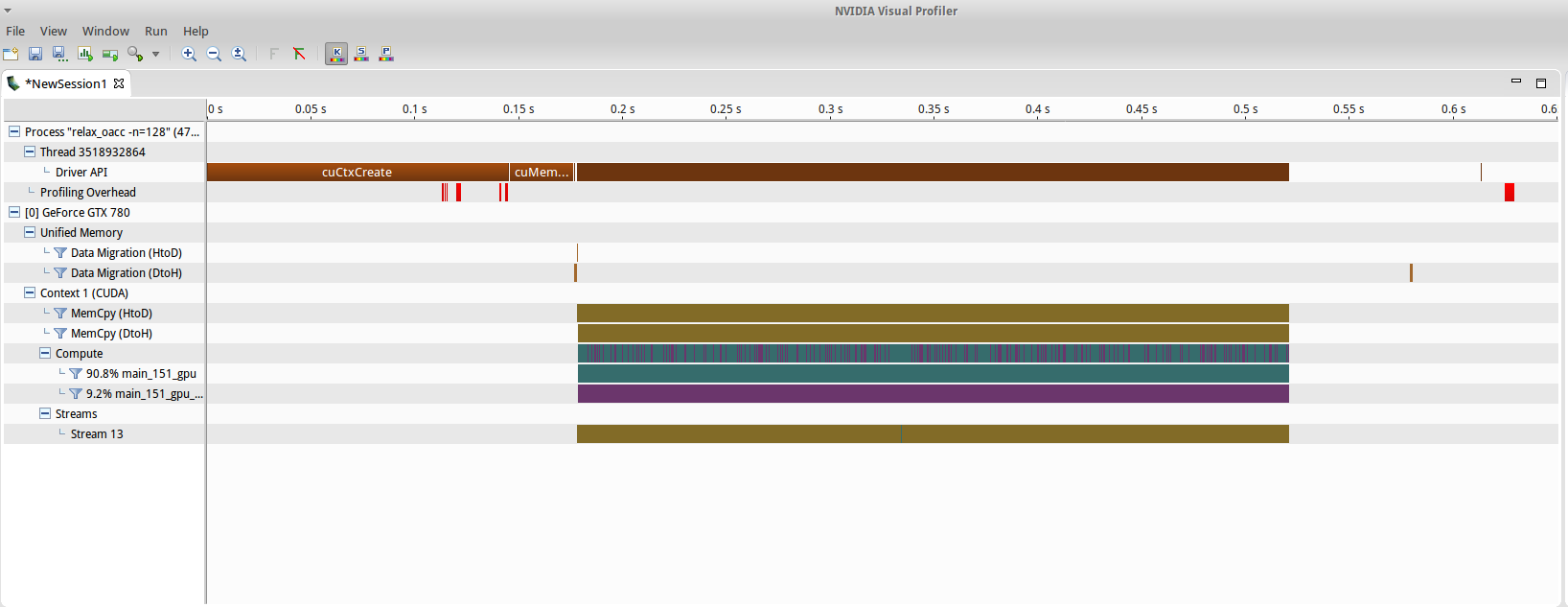
./relax_oacc -n=128 run. Complete profiling output in NVVP.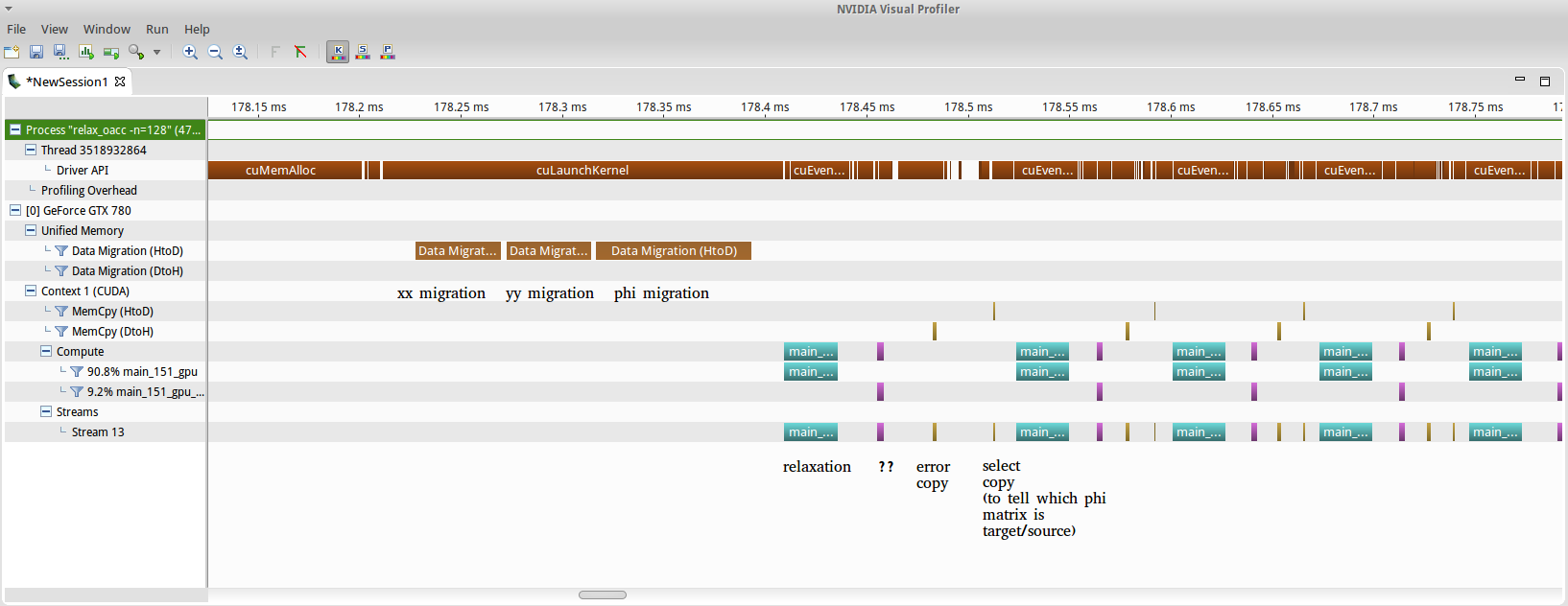
./relax_oacc -n=128 run. More detailed profiling for the start of the relaxation work. Annotations were added to identify each operation. I am not 100% sure what the purple kernel is for, but IÆm guessing maybe it has to do with reduction of the error variable from each blockÆs output. The kernel for 128x128 relaxation (teal) executes in ~25us. The two memory transfers are 4B up/down for the status variables ōerrorö and ōselectö. Note that the theoretical occupancy is 100%, which means OpenACC is pretty good at automatically optimizing block sizes.I did try to see what happens when you try and compile code for an SLI enabled system: it doesnÆt work. SLI support in Linux is historically bad (I have to disable my dual monitor settings if I turn it on, for example), and there are seemingly some issues with the GPUs handling instruction sets in the same way. Inexplicably, the program still produces the correct data, but the execution time of the kernels (the time it takes for a single iteration) increases 30 fold (thereby elminiating any and all speedup), as seen in fig9. TLDR: donÆt use SLI here.
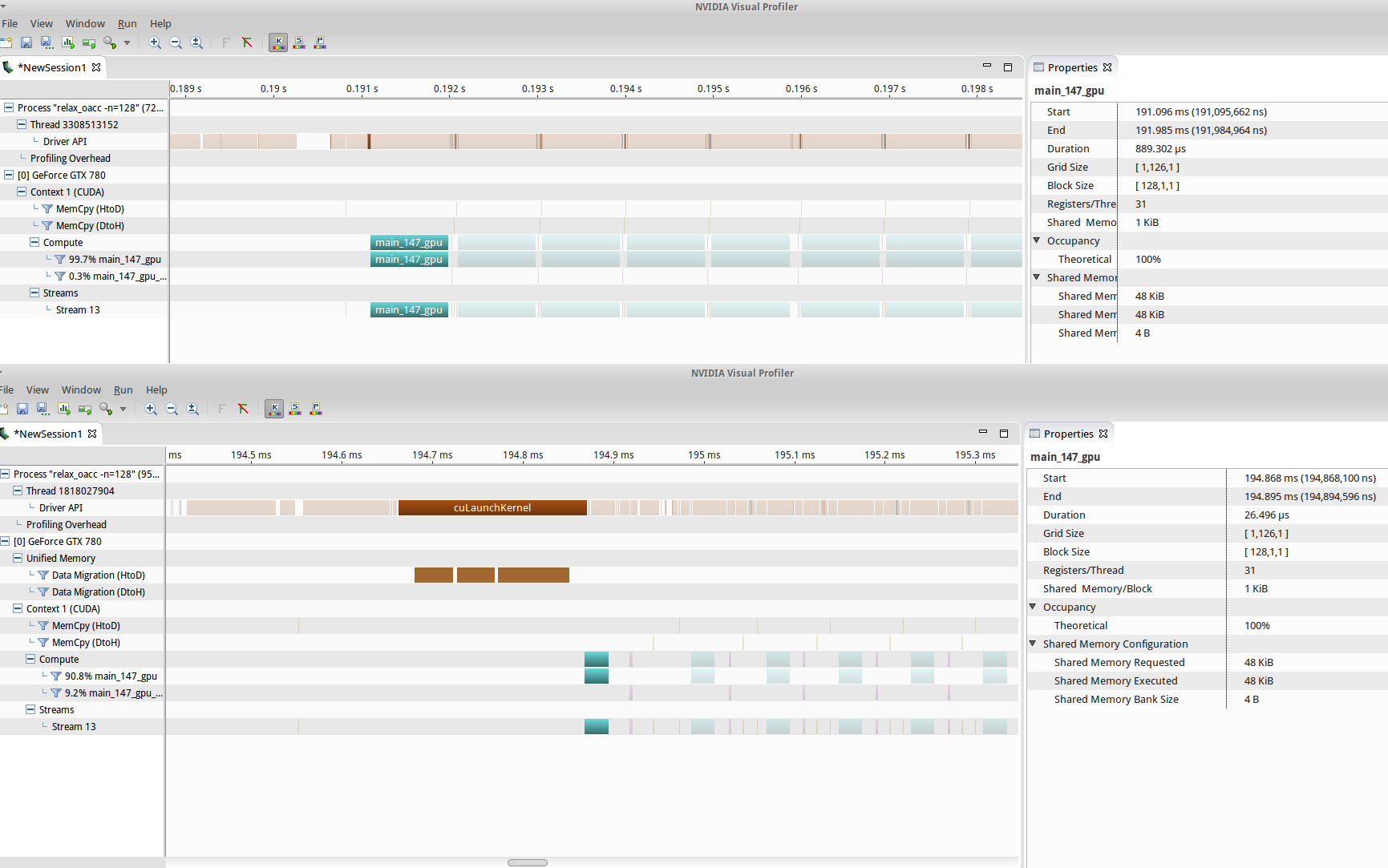
./relax_oacc -n=128 run with (top) and without (bottom) SLI enabled in an Ubuntu 14.04 environment with CUDA 7.5.17, 352.30 drivers and PGI compilers v15.7. SLI was enabled with sudo nvidia-xconfig -sli=On and a restart of lightdm from tty0. Something seems to be broken in the SLI implementation either with the driver or with CUDA (or with the CUDA generated by OpenACC, for that matter) as the kernel computation time itself, for a single relaxation, is inexplicably increased > 30 fold.Though p4ac does compile correctly, and execute without fatal error, the output data is not correct, as shown earlier. I did profile it, however, for ōeducational reasonsö and we can see that an additional kernel was added to do the A <-> Anew copy, as expected fig10.
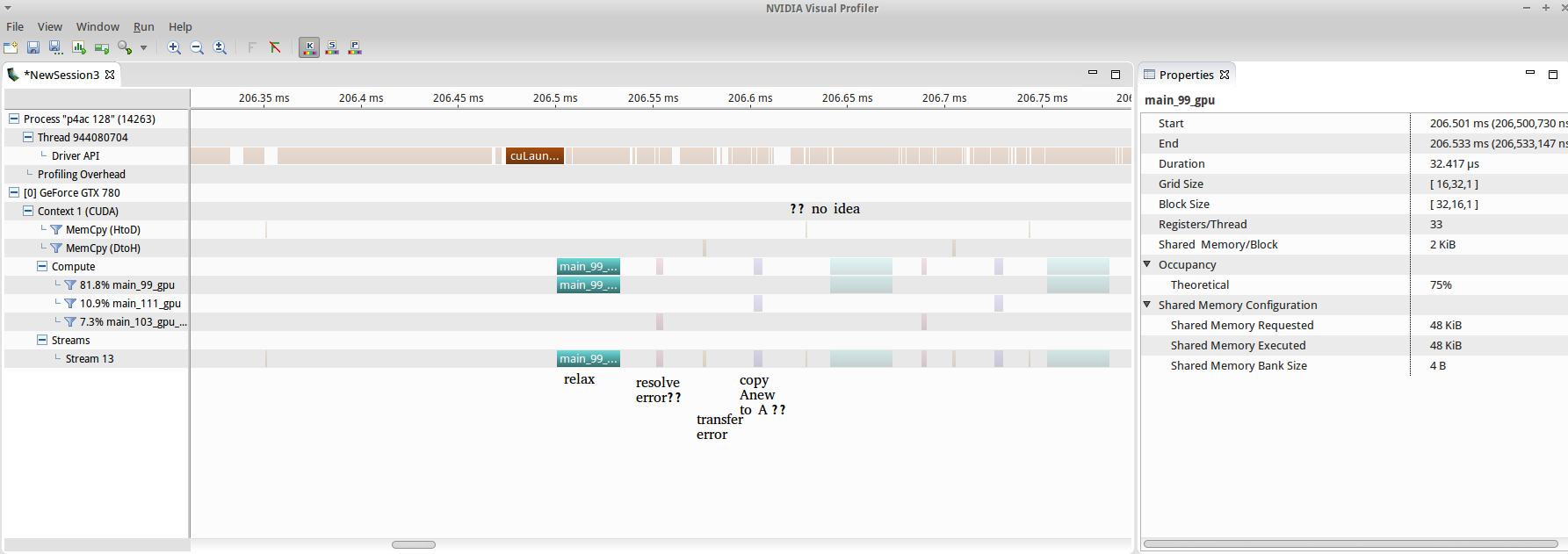
./p4ac 128 run. The OpenACC accelerated version of the C Jacobi Iteration program does compile and execute without failure, but the result, as shown in fig3, is not correct, so I will not benchmark it here, or comment on itÆs general performance.As shown by the benchmarking for Jackson in fig11 the OpenACC speedup is gigantic. Three lines of code = 30x speedup. If thatÆs not a good deal I donÆt know what is.
6.3 Benchmarking
Benchmarking was completed for all functioning executables for varying grid sizes (chosen to minimize time spent waiting for the single threaded versions to finishģ). The results were what you would expect: OpenACC > OpenMP > Single Thread. However, there are two points worth discussing.
First, the number of iterations required for convergence was higher for Jackson at larger grid sizes. In general, you would expect Jackson to converge faster than p4a, as it uses dual meshes. However, I suspect that the more difficult boundary conditions (a circular step function) played a role in this effect.
| Grid Size | Jackson Iterations | P4A Iterations |
|---|---|---|
| 128 x 128 | 3232 | 7600 |
| 256 x 256 | 9356 | 14351 |
| 512 x 512 | 22954 | 20098 |
| 1024 x 1024 | 30500 | 23051 |
error = 1.0e-5f;. Interestingly enough, Jackson seems to require more iterations after a certain grid size. Since Jackson uses a dual mesh method, one would expect it to converge with less iterations in general.Second, it is quite clear, at least with the GNU OpenMP implementation, that you need a reduction clause for the error variable for any useful acceleration to occur. As seen in fig11 and fig12, removing this clause will drastically reduce speedup, eliminating it entirely for the p4a version. As stated previously, the Parallel For All code used PGI compilers and passed a -fast flag, which probably optimized this automatically. Using GNU OpenMP, one has to, seemingly, implement this manually.
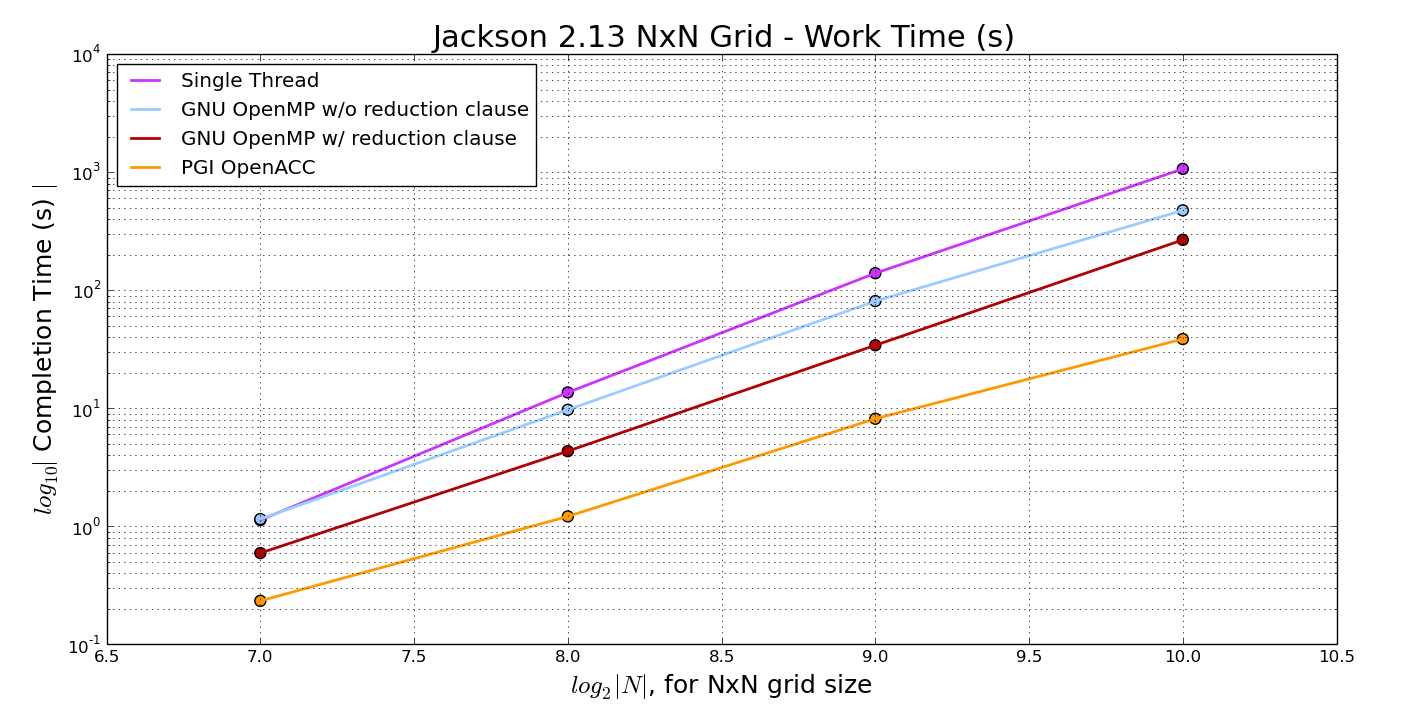
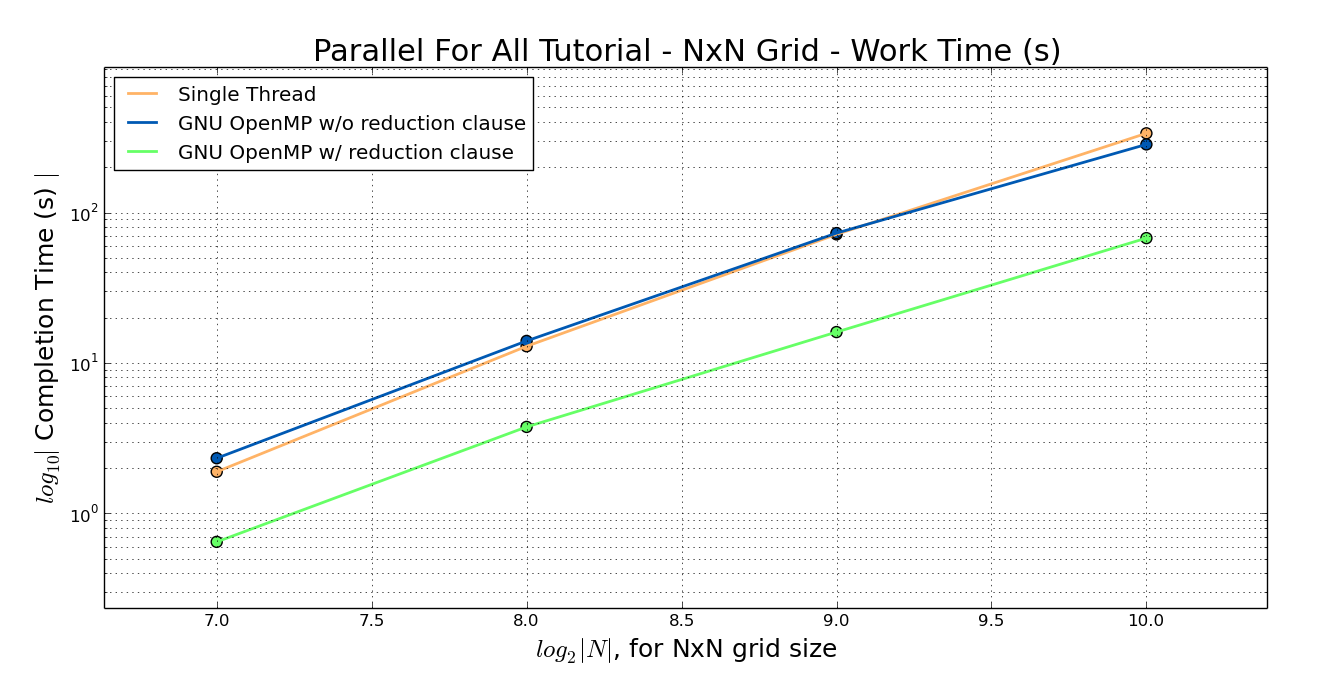
From Mathew Colgrove, a Portland Group engineer who helped me solve some technical issues:
Excellent result. This is normal speed-up for a single compute intensive loop such as this. IÆve even seen as high as 70x with one directive (an MRI code). Once you start porting larger application which includes more data movement and less compute intensive parts of your code, the speed-up of a single Tesla K80 over a 32 core Haswell system is more likely to be in the 2-4x range. Still quite impressive though.
7 Conclusion
Conclusion 1: Use OpenACC**.
Conclusion 2: DonÆt not use OpenACC**.

** Except for in applications with low compute intensities and/or complicated thread interdependencies. In general, the more complicated it is the more likely youÆll want to devote time to environment specific (CUDA/OpenCL/C++11/14 (std::thread)) development.
Also, Jacobi Iteration is fairly primitive and slow, but itÆs easy to get up and running, hence my use of it here. There are much faster iterative methods for solving PDEs, such as Gauss-Sidel/Successive Over-Relaxation (same thing, basically) that also have the benefit of being in-place. I may implement either or both of these in the future just to compare performance. In terms of accuracy FEM algorithms are usually more precise, and are useable for a much wider range of geometries (not just rectangular grids like FDM).